


- What Are LLM Fine-Tuning Datasets?
- Why Conversational Datasets Drive LLM Performance
- Types of Conversational AI Datasets
- Step-by-Step Process to Create LLM Fine-Tuning Datasets
- Best Practices for Building High-Quality Chatbot Training Data
- Common Challenges in Creating Conversational AI Datasets
- How Macgence Helps Build LLM Fine-Tuning Datasets
- Securing Your Enterprise AI Success
- Frequently Asked Questions
How to Build Conversational Datasets for LLMs
Large Language Models (LLMs) like GPT, Llama, Claude, and Mistral have rapidly transformed the artificial intelligence landscape. These massive base models boast incredible capabilities, generating coherent text and solving complex problems right out of the box. However, despite their impressive power, base models remain fundamentally generic. They know a little bit about everything but lack the specialized knowledge required for specific business applications.
Organizations must adapt these foundation models with domain-specific information to build reliable chatbots, virtual assistants, and enterprise AI systems. This is where LLM fine-tuning datasets come into play. By exposing the model to targeted, highly relevant examples, businesses can shape its behavior, tone, and accuracy. Conversational datasets form the absolute foundation of this fine-tuning process.
Ultimately, the quality of your conversational AI datasets determines how accurate, helpful, and safe a customized model becomes. Garbage in leads to garbage out, while highly structured, clean data produces an enterprise-grade assistant. This guide explores everything you need to know about preparing this data. We will cover what conversational datasets actually are, why they matter so much, a step-by-step creation process, best practices for quality control, and the common challenges teams face along the way.
What Are LLM Fine-Tuning Datasets?
LLM fine-tuning datasets are carefully curated collections of text used to adapt a pre-trained language model to a specific task or domain. To understand their role, it helps to look at the difference between pretraining datasets and fine-tuning datasets. Pretraining datasets are massive, unstructured scrapes of the internet that teach a model the basic rules of human language. Fine-tuning datasets, on the other hand, are smaller, highly structured collections of examples that teach the model exactly how to behave in a specific context.
By relying on these targeted examples, fine-tuning datasets help models follow instructions accurately, maintain a natural conversation flow, and align with specific business goals. They also enable the AI to generate highly domain-specific answers instead of generic guesses.
These datasets come in several formats depending on the end goal. Common structures include instruction-response pairs, multi-turn dialogues, question-answer pairs, and chat-style datasets. A typical example might look like this:
User: How do I reset my banking password?
Assistant: To reset your banking password, follow these steps. First, navigate to the login page and click “Forgot Password.” Then, enter your account email address to receive a reset link.
High-quality conversational AI datasets power the most effective customer support chatbots, virtual assistants, and enterprise copilots on the market today.
Why Conversational Datasets Drive LLM Performance
Using chat-style data significantly improves an LLM’s functional capabilities. One of the primary benefits is better context handling. When models learn from multi-turn dialogue understanding, they remember what a user said earlier in the conversation, leading to a much smoother user experience.
Improved response relevance is another major advantage. High-quality chatbot training data helps produce context-aware answers that actually solve the user’s problem. Furthermore, fine-tuning datasets inject vital domain expertise into the model. Whether an organization operates in finance, healthcare, or ecommerce, targeted data ensures the AI understands industry-specific terminology and procedures.
Brand voice alignment represents another crucial benefit. Companies can train models to follow specific guidelines regarding tone, internal policy, and regulatory compliance. You can see these benefits clearly in modern use cases like customer support AI, AI sales assistants, HR chatbots, banking assistants, and healthcare triage bots.
However, building effective LLM fine-tuning datasets requires a structured pipeline to ensure the data is actually useful.
Types of Conversational AI Datasets
Different applications require different styles of conversational data. Here are the three main types used for fine-tuning.
Instruction–Response Datasets
This is a simple, highly structured format where a direct prompt is followed by a direct answer.
Instruction: Summarize the meeting notes.
Response: The meeting covered the new Q3 marketing budget, the upcoming product launch timeline, and assigned task leads for the development team.
Developers commonly use this format for instruction-tuned models and task-based assistants that need to perform specific, isolated actions.
Multi-Turn Dialogue Datasets
This format captures the back-and-forth flow of a real conversation.
User: What is the return policy?
Assistant: Our return policy allows returns within 30 days of purchase.
User: Do I need the original receipt?
Assistant: Yes, the original receipt helps us process the return much faster.
Multi-turn datasets are incredibly important for chatbot training data and building fluid conversational AI systems.
Domain-Specific Conversations
These datasets focus heavily on niche industry knowledge. Examples include medical support chat logs, secure banking queries, and ecommerce product assistance. These specific datasets help LLMs specialize in complex industries where generic answers could cause serious problems.
Step-by-Step Process to Create LLM Fine-Tuning Datasets
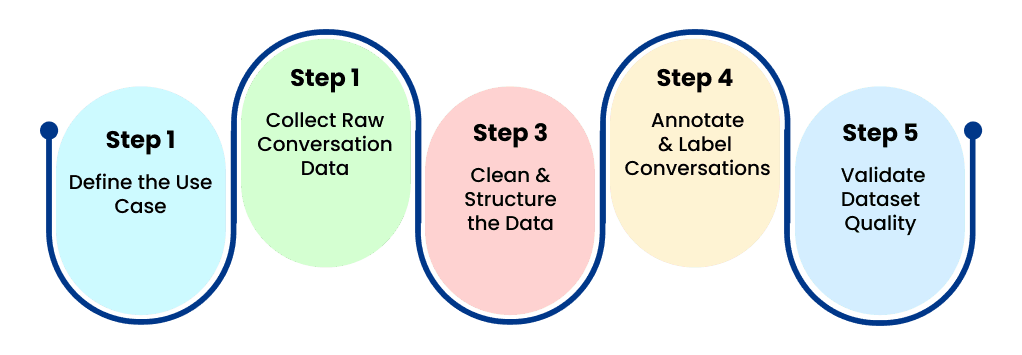
Creating high-quality data requires a methodical approach. Follow these core steps to build effective datasets.
Step 1: Define the Use Case
Start by identifying the exact purpose of the chatbot. Who are the target users? What specific tasks are they expected to accomplish? Examples might include handling tier-one customer support, acting as an internal knowledge assistant, or operating a technical help desk. Clear objectives ensure your dataset remains relevant to the actual business need.
Step 2: Collect Raw Conversation Data
Next, gather the raw text that will form the basis of your dataset. Sources typically include customer support chat logs, email conversations, historical support tickets, and comprehensive FAQ databases. You can also use human-written dialogue scripts. It is incredibly important during this phase to remove sensitive information and ensure total privacy compliance before moving forward.
Step 3: Clean and Structure the Data
Raw conversations are rarely ready for model training. You must convert them into structured LLM fine-tuning datasets. Key steps involve removing irrelevant text or system artifacts, normalizing the formatting, and splitting the text into clear dialogue turns. You must maintain the conversation context throughout this process.
A structured JSON format often looks like this:
{
“messages”:[
{“role”:”user”,”content”:”How do I track my order?”},
{“role”:”assistant”,”content”:”You can track your order by logging into your account and clicking ‘Order History’.”}
]
}
Step 4: Annotate and Label Conversations
Human annotators drastically improve dataset quality. Annotation work may include intent tagging, defining conversation roles, response ranking, sentiment tagging, and safety labeling. High-quality annotation ensures the model aligns perfectly with human expectations.
Step 5: Validate Dataset Quality
Before initiating the training process, all datasets should undergo rigorous quality checks. This includes consistency validation, a thorough bias review, and response accuracy verification. Enterprises often rely on professional data annotation providers to maintain these high-quality standards at scale.
Best Practices for Building High-Quality Chatbot Training Data
Following established guidelines will save you time and money during the fine-tuning process.
- Maintain Conversation Diversity: Include a healthy mix of simple questions, complex multi-step queries, and natural follow-up questions.
- Avoid Repetitive Patterns: Overly repetitive responses can cause models to overfit, making them sound robotic and inflexible.
- Balance Conversation Length: Mix short, transactional interactions with longer, multi-turn dialogues.
- Include Edge Cases: Train the model on unclear questions, incomplete queries, negative feedback, and sarcastic inputs. This drastically improves LLM robustness in the real world.
- Use Human-in-the-Loop Validation: Expert human reviewers help ensure factual accuracy, safe responses, and perfect brand alignment.
Common Challenges in Creating Conversational AI Datasets
Teams building enterprise AI often run into a few realistic obstacles during data preparation.
Data privacy concerns rank near the top of the list. Real customer conversations frequently contain sensitive, personally identifiable information that must be thoroughly scrubbed. Additionally, annotation complexity poses a major hurdle. Structuring and labeling multi-turn dialogues accurately requires highly experienced annotators.
Maintaining dataset quality is another continuous battle. Poorly structured data quickly leads to model hallucinations and inaccurate outputs. Finally, scaling dataset creation is incredibly difficult for internal teams. Large-scale LLM projects often require hundreds of thousands, or even millions, of conversations. This is exactly where specialized AI data providers step in to help scale dataset creation efficiently.
How Macgence Helps Build LLM Fine-Tuning Datasets
Macgence helps forward-thinking organizations create enterprise-grade conversational datasets without the operational headaches. Through custom LLM fine-tuning datasets, human-in-the-loop data annotation, and multilingual conversational AI datasets, Macgence provides the foundation for superior AI models.
Our comprehensive services include end-to-end chatbot training data creation, along with rigorous dataset validation and quality checks. Partnering with Macgence offers significant advantages, including access to domain-expert annotators, scalable dataset generation, and highly secure data pipelines. We deliver tailored datasets built specifically for your unique AI applications. This ultimately enables companies to fine-tune LLMs faster, safer, and with significantly higher accuracy.
Securing Your Enterprise AI Success
Conversational datasets serve as the absolute backbone of LLM fine-tuning. High-quality chatbot training data directly improves response accuracy, contextual understanding, and deep domain expertise. However, building these datasets requires highly structured data pipelines, expert human annotation, and strict quality control measures. Organizations building AI assistants, customer support chatbots, or internal enterprise copilots should invest in high-quality LLM fine-tuning datasets today to ensure reliable, safe model performance tomorrow.
Frequently Asked Questions
LLM fine-tuning datasets are structured training datasets used to adapt large language models to specific tasks, domains, or conversational styles.
Pretraining datasets teach models general language patterns, while fine-tuning datasets train them for specific tasks such as customer support or chatbot conversations.
Conversational AI datasets are typically structured as multi-turn dialogues with user and assistant roles, often stored in JSON or chat-style formats.
Depending on the model and task, fine-tuning may require thousands to millions of conversation examples.
Yes. Organizations can generate chatbot training data using customer interactions, FAQs, and expert-written conversations, often supported by professional data annotation providers.
Human annotators help ensure accuracy, contextual relevance, and safety, which significantly improves LLM performance.
 Previous Blog
Previous Blog



You Might Like

April 27, 2026
Powering Robotics AI With Activity Recognition
Robotics automation is undergoing a massive transformation. We are moving away from simple, rule-based machines and entering an era of AI-driven perception. Robots no longer just perform repetitive tasks; they observe, interpret, and react to human behavior in real time. Understanding human activities is especially critical in complex physical spaces like stores and factories. This […]

April 25, 2026
Building a High-Quality Robot Perception Dataset
Robot perception serves as the backbone of embodied AI. Without the ability to accurately see, hear, and feel their surroundings, machines cannot interact safely with the physical environment. A robot perception dataset provides the essential sensory inputs—like vision, depth, and tactile feedback—that train these systems to understand the world around them. When developers rely on […]

April 24, 2026
Advanced Robotics Data Types: From Trajectories to 3D Hand Meshes
The field of artificial intelligence is experiencing a massive shift. We are moving away from simple labeled datasets toward complex, multimodal robotics data. Early AI models relied heavily on static images and text, but embodied AI and modern robot learning require something much more robust. To interact with the physical world, robots need high-fidelity data […]