


- What Are ASR Training Datasets?
- Why Real Customer Conversations Are Critical for ASR Accuracy
- Common Challenges in Using Real Customer Speech Data
- How Real Customer Conversations Improve ASR Training
- Key Data Requirements for Training ASR with Real Speech
- Best Practices for Preparing Real Speech Data for ASR Training
- Synthetic vs Real Speech Data: A Practical Comparison
- Industry Use Cases for Real Customer Conversation Data
- How to Build High-Quality ASR Training Datasets from Customer Conversations
- Why Enterprises Are Moving Toward Real Speech Data for ASR Training
- Choosing the Right Partner for ASR Training Datasets
- Building the Future of Speech Recognition
Training ASR Models with Real Customer Conversations
Automatic Speech Recognition (ASR) systems power voice assistants, transcription tools, and customer service bots. Yet despite impressive accuracy scores in controlled lab environments, many ASR models stumble when deployed in production. The reason? They’re trained on clean, scripted data that doesn’t reflect how people actually speak.
Real customer conversations are messy. They include interruptions, background noise, accents, slang, and emotional tones that scripted datasets simply can’t replicate. When ASR models train on authentic speech data, they learn to handle these real-world complexities, leading to better performance where it matters most—in live production environments.
This guide explores why real customer conversations are critical for building robust ASR training datasets, the challenges involved, and practical strategies for leveraging authentic speech data to improve your models.
What Are ASR Training Datasets?
ASR training datasets are collections of audio recordings paired with accurate text transcriptions. These datasets teach machine learning models to convert spoken language into written text by exposing them to diverse speech patterns, vocabulary, and acoustic environments.
A comprehensive ASR training dataset typically includes:
- Audio recordings: Raw speech data captured in various formats and quality levels
- Transcriptions: Word-for-word text representations of the audio
- Speaker metadata: Information about speaker demographics, accents, and dialects (optional but valuable)
- Noise and accent variations: Environmental sounds and regional speech patterns that reflect real-world conditions
Speech recognition datasets can be sourced in three primary ways:
Scripted datasets feature actors or volunteers reading from prepared scripts in controlled studio conditions. While these produce clean audio and accurate transcriptions, they lack the spontaneity and variability of natural speech.
Synthetic speech is generated entirely by text-to-speech systems. This approach offers unlimited scalability and perfect transcription alignment, but the resulting audio often sounds robotic and fails to capture human speech nuances.
Real customer conversation data captures authentic interactions between people—whether through call centers, voice assistants, or support channels. This data includes natural speech patterns, emotional inflections, and environmental noise that make ASR models more robust and production-ready.
Why Real Customer Conversations Are Critical for ASR Accuracy
Laboratory-perfect datasets might achieve impressive Word Error Rate (WER) scores during testing, but those numbers often don’t translate to real-world performance. Here’s why authentic speech data makes the difference:
Real-world speech is inherently messy. Customers interrupt themselves mid-sentence, use filler words like “uh” and “um,” speak with regional slang, and communicate in environments filled with background noise. They express emotion through tone—frustration, excitement, confusion—that affects pronunciation and cadence. These characteristics are nearly impossible to replicate in scripted recordings.
The performance gap between models trained on scripted data versus real speech becomes evident when deployed. An ASR system that achieves 95% accuracy on clean test data might drop to 75% accuracy when processing actual customer calls. That 20-point difference translates directly to business impact.
Training on real customer conversations delivers measurable business benefits:
- Lower Word Error Rate (WER): Models achieve more accurate transcriptions because they’ve learned from speech patterns that match production environments
- Better intent recognition: Understanding what customers actually mean—not just what they say—improves when models train on authentic conversations
- Improved user experience: Fewer transcription errors mean smoother interactions, less customer frustration, and higher satisfaction scores
Real speech data doesn’t just improve accuracy metrics. It makes your ASR system more resilient to the unpredictable nature of human communication.
Common Challenges in Using Real Customer Speech Data
While real customer conversations produce superior ASR models, working with this data introduces unique challenges that organizations must address:
Data Privacy and Compliance
Customer conversations often contain sensitive information—names, addresses, payment details, medical records. Collecting and processing this data requires strict adherence to privacy regulations like GDPR and HIPAA.
Organizations must obtain proper consent before recording conversations, implement robust anonymization processes to remove personally identifiable information, and use redaction techniques to mask sensitive data in transcriptions. These compliance requirements add complexity but are non-negotiable when working with real customer data.
Poor Audio Quality
Unlike studio recordings, real customer calls suffer from technical limitations. Call center environments introduce background chatter and equipment noise. Multiple speakers often talk simultaneously, making it difficult to isolate individual voices. Mobile phone connections create compression artifacts and signal distortion that degrade audio quality.
These quality issues make transcription more challenging and require sophisticated preprocessing to clean and segment audio effectively.
Annotation Complexity
Transcribing real conversations demands more expertise than scripted speech. Annotators must handle overlapping dialogue between multiple speakers, identify code-switching when speakers alternate between languages, and accurately capture domain-specific terminology that may not appear in standard dictionaries.
The human effort required for high-quality annotation of authentic speech data is substantial. However, this investment pays dividends in model performance.
These challenges are solvable with the right expertise and infrastructure. A reliable data partner can navigate compliance requirements, implement quality control processes, and deliver annotated datasets that meet production standards.
How Real Customer Conversations Improve ASR Training
Training ASR models on authentic customer interactions provides advantages that synthetic and scripted data simply cannot match:
Accent and dialect coverage: Real conversations naturally include the full spectrum of regional accents and dialects your customers actually use. Rather than attempting to predict which variations matter, you capture them organically through authentic speech.
Natural sentence structures: People don’t speak in perfect grammatical sentences. They use contractions, fragments, run-on thoughts, and colloquialisms. Models trained on these patterns learn to interpret natural language as it’s actually spoken.
Domain vocabulary: Every industry has specialized terminology. Banking customers discuss “wire transfers” and “APR.” Healthcare conversations mention symptoms and medications. E-commerce interactions reference products and shipping. Real customer data ensures your model masters the vocabulary that matters for your specific use case.
Edge cases: Authentic speech data captures scenarios that are difficult to anticipate—angry customers speaking rapidly, children’s voices in the background, moments of laughter or crying, technical glitches that distort audio. These edge cases might seem minor, but they’re exactly where ASR systems often fail in production.
Models trained on real customer conversations adapt better to live production environments because they’ve already encountered the full complexity of human speech. They’re not surprised by unexpected patterns—they’ve seen them during training.
Key Data Requirements for Training ASR with Real Speech

Building effective ASR training datasets from customer conversations requires attention to several critical components:
- High-quality audio collection: Capture audio at appropriate sample rates (typically 16 kHz minimum for speech) and bit depths. Maintain consistent recording parameters across your dataset.
- Clean transcription guidelines: Establish clear rules for how annotators should handle challenging scenarios—abbreviations, numbers, technical terms, and unclear speech. Consistency in transcription style directly impacts model performance.
- Speaker labeling: Identify and label different speakers in multi-party conversations. This enables models to better separate overlapping speech and improve accuracy in conversational contexts.
- Noise tagging: Annotate environmental sounds, background speech, and audio artifacts. This metadata helps models learn to distinguish between target speech and noise.
- Intent or emotion tagging: Optional but valuable metadata that captures the speaker’s intent or emotional state. This additional context can improve understanding in conversational AI applications.
These requirements form the foundation of production-ready speech recognition datasets. Cutting corners during data preparation inevitably compromises model performance.
Best Practices for Preparing Real Speech Data for ASR Training
Successfully leveraging customer conversations for ASR training requires systematic approaches to data collection, cleaning, and annotation:
Data Collection Strategies
Multiple sources provide access to authentic customer speech:
- Call center recordings: Customer service interactions offer rich, domain-specific conversations with natural question-and-answer patterns
- Chatbot voice logs: Voice-enabled chatbots capture goal-oriented conversations in various contexts
- IVR systems: Interactive Voice Response systems record how customers navigate automated menus and provide information
- Customer support calls: Technical support conversations include problem descriptions and troubleshooting dialogue
Each source contributes different speech patterns and use cases to your training data.
Data Cleaning and Normalization
Raw audio requires preprocessing before annotation:
- Removing silence: Trim long pauses and dead air to focus on actual speech content
- Audio segmentation: Split long recordings into manageable segments, typically 10-30 seconds each
- File format standardization: Convert all audio to consistent formats (WAV or FLAC) with uniform sample rates and encoding
These steps ensure consistency across your dataset and make annotation more efficient.
Transcription and Annotation
High-quality transcription is labor-intensive but critical:
- Human-in-the-loop annotation: Combine automated transcription tools with human review to balance efficiency and accuracy
- Quality assurance: Implement multiple review passes to catch errors and ensure consistency
- Multi-pass review: Have different annotators review the same audio to identify discrepancies and improve accuracy
Professional annotation services with experienced teams can significantly accelerate this process while maintaining quality standards.
Synthetic vs Real Speech Data: A Practical Comparison
Both synthetic and real speech data have roles in ASR development. Understanding their tradeoffs helps you make informed decisions:
| Factor | Synthetic Speech | Real Speech Data |
| Accuracy | Good for basic models, struggles with natural variation | Excellent for production models, handles real-world complexity |
| Cost | Low—algorithmically generated | Higher—requires collection, annotation, and compliance |
| Time | Fast—generate unlimited data instantly | Slower—dependent on collection and annotation capacity |
| Scalability | Unlimited generation capacity | Limited by available authentic recordings |
| Bias | Can perpetuate training data biases | Reflects actual customer demographics and speech patterns |
Synthetic data helps bootstrap models and fill gaps in training coverage. However, real speech data is required for production-level ASR systems that must perform reliably with actual users. The most effective approach often combines both: use synthetic data for initial model development, then refine and validate with real customer conversations.
Industry Use Cases for Real Customer Conversation Data
Organizations across industries leverage authentic speech data to power ASR applications:
Customer support automation: Transcribe and analyze support calls to route inquiries, extract common issues, and generate insights that improve service quality.
Voice bots and virtual assistants: Train conversational AI systems to understand natural customer requests and respond appropriately, reducing friction in automated interactions.
Call analytics systems: Analyze thousands of customer conversations to identify trends, measure sentiment, and evaluate agent performance at scale.
Healthcare dictation tools: Enable physicians to dictate clinical notes using medical terminology and natural speech patterns, improving documentation efficiency.
Financial service IVR systems: Process customer voice input for account access, transaction requests, and automated banking services with high accuracy.
Each application benefits from training data that matches its specific domain and use case. Generic ASR models trained on broad datasets rarely achieve optimal performance for specialized applications.
How to Build High-Quality ASR Training Datasets from Customer Conversations
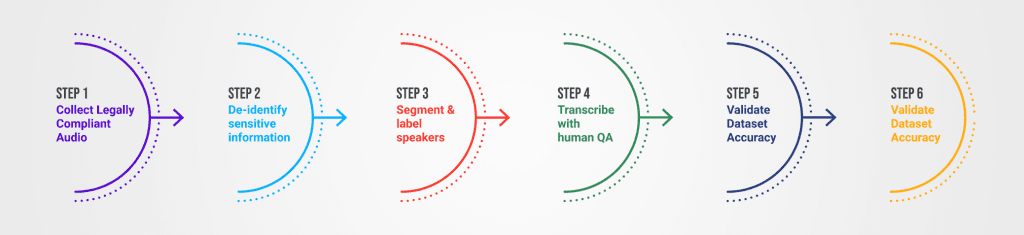
Creating production-ready datasets requires a systematic approach:
Step 1: Collect legally compliant audio
Ensure proper consent mechanisms are in place and recordings comply with relevant privacy regulations. Document your data collection processes for audit purposes.
Step 2: De-identify sensitive information
Remove or mask personally identifiable information from both audio and transcriptions. Use automated detection tools combined with human review for comprehensive coverage.
Step 3: Segment and label speakers
Split audio into manageable segments and identify individual speakers. This enables more accurate transcription and better model training.
Step 4: Transcribe with human QA
Generate initial transcriptions using automated tools, then have experienced annotators review and correct them. Implement quality assurance processes to maintain consistency.
Step 5: Validate dataset accuracy
Review a sample of annotated data to verify quality meets your standards. Calculate inter-annotator agreement scores to identify areas needing improvement.
Step 6: Train and test ASR model
Use your prepared dataset to train models, then evaluate performance against held-out test data that represents real production conditions.
This process requires domain expertise and scalable annotation infrastructure. Organizations serious about production-grade ASR often partner with specialized providers to access this capability.
Why Enterprises Are Moving Toward Real Speech Data for ASR Training
The ASR industry is experiencing a fundamental shift from laboratory datasets to production-focused data collection:
From lab datasets to production datasets: Organizations recognize that accuracy in controlled environments doesn’t guarantee real-world performance. Investment is shifting toward data that reflects actual usage conditions.
Need for multilingual and regional accent support: Global businesses must serve diverse customer bases. Real speech data naturally captures the linguistic diversity required for international deployment.
AI models trained on clean data failing in real world: High-profile ASR failures have highlighted the gap between test performance and production reliability. Real speech data addresses this directly.
Data-driven competitive advantage: Companies that invest in high-quality, domain-specific ASR training datasets create sustainable competitive advantages. Their voice systems work better, leading to superior customer experiences and operational efficiency.
The trend toward authentic speech data isn’t temporary—it reflects the maturation of ASR technology from research novelty to business-critical infrastructure.
Choosing the Right Partner for ASR Training Datasets
Building production-ready ASR training datasets internally requires significant investment in infrastructure, expertise, and compliance frameworks. Many organizations choose to partner with specialized providers who bring:
Experience with speech data: Deep expertise in audio collection, preprocessing, and annotation for ASR applications. Knowledge of common pitfalls and best practices accumulated across multiple projects.
Security and compliance: Established processes for handling sensitive customer data while maintaining GDPR, HIPAA, and industry-specific compliance requirements.
Custom dataset creation: Ability to collect and annotate speech data tailored to your specific domain, use case, and target demographics.
Domain-specific expertise: Understanding of industry terminology and requirements that ensures annotations accurately capture specialized vocabulary and concepts.
Scalability: Infrastructure and workforce capable of handling projects from pilot datasets to enterprise-scale data collection and annotation.
A reliable data partner like Macgence can deliver secure, annotated, and production-ready ASR training datasets tailored to your industry. With experience across multiple domains and global sourcing capabilities, specialized providers accelerate your path from concept to deployed ASR system.
Building the Future of Speech Recognition
Real customer conversations represent the frontier of ASR development. While synthetic and scripted data have their place in model prototyping, authentic speech data is what separates laboratory demonstrations from production-ready systems.
The benefits are measurable: lower word error rates, better intent recognition, and improved user experiences. The challenges—privacy compliance, audio quality, annotation complexity—are surmountable with proper expertise and infrastructure.
Quality ASR training datasets define the success of your speech recognition initiatives. Models can only learn what they’re taught. Feed them authentic, diverse, carefully annotated customer conversations, and they’ll handle the complexity of real-world speech.
If you’re building production-ready ASR systems, real speech data is no longer optional. It’s the foundation for models that actually work when deployed to serve your customers.

You Might Like

April 8, 2026
Why Data is the Real Bottleneck in Embodied AI Training
AI is moving off our screens and into the physical world. For years, artificial intelligence lived exclusively on servers and smartphones. Now, it is driving autonomous systems, powering delivery robots, and animating humanoids. This transition from software-only models to physical agents represents a massive shift in how machines interact with human environments. While there is […]

April 7, 2026
Why Synthetic Speech Data Isn’t Enough for Production AI
The voice AI market is experiencing explosive growth. From virtual assistants and call automation systems to interactive voice bots, companies are racing to build intelligent audio tools. To meet the demand for training information, developers are increasingly turning to synthetic speech data as a fast, highly scalable solution. Because of this rapid adoption, a common […]

April 6, 2026
Where to Buy High-Quality Speech Datasets for AI Training?
The demand for intelligent voice assistants, call analytics software, and multilingual AI models is growing rapidly. Developers are rushing to build smarter tools that understand human nuances. But the biggest challenge engineers face isn’t writing better algorithms. The main hurdle is finding reliable, scalable, and high-quality audio collections to train their models effectively. Training a […]