


- Introduction
- What is RLHF?
- Why Does RLHF Matter?
- How RLHF Works?
- RLHF Workflow: (From Pretraining to Fine-Tuning)
- Key Terminologies in RLHF
- Applications of RLHF in AI Systems
- Real-World Case Studies of RLHF in Action
- Key Benefits of RLHF Training
- Statistics on the Impact of RLHF on AI Model Performance
- Is RLHF Right for Your Organization?
- RLHF Training Checklist
- Common RLHF Challenges and Solutions
- RLHF Across Buyer Journey
- Conclusion
- FAQ's
- Related Resouces
RLHF: Explained and Use Cases 2025
Introduction
Reinforcement Learning from Human Feedback (RLHF) is reshaping how machines learn by blending human intuition with machine efficiency. Unlike traditional training methods that rely on predefined datasets, It allows AI models to learn from preferences, corrections, and insights provided directly by humans. This approach helps align machine behavior with real-world values, making AI systems more reliable, ethical, and context-aware. From chatbots to autonomous systems, It plays a crucial role in fine-tuning models for complex, nuanced tasks.
In this article, we’ll explore how RLHF works, its benefits, real-world applications, and why it’s becoming essential in responsible AI development.
What is RLHF?
It stands for Reinforcement Learning from Human Feedback, which is a technique where human preferences guide the learning process of AI models. Unlike traditional reinforcement learning that depends on reward signals from environments, It integrates human-generated data, like rankings, corrections, and choices, to shape model behavior.
Why Does RLHF Matter?
- Better Alignment with Human Intentions: It enables AI systems to better understand and reflect human values.
- Safety and Ethics: Ensures models avoid harmful, biased, or toxic outputs.
- Generalization: Helps models learn tasks without explicit programming.
How RLHF Works?
Step 1. Pre-training: A large dataset is used to train a foundational model.
Step 2. Supervised Fine-tuning: Human-labeled datasets refine the model’s responses.
Step 3. Reward Modeling: Humans rank outputs, and a reward model is created.
Step 4. RLHF Training: Reinforcement Learning is used to fine-tune the model with the reward model guiding optimization.
RLHF Workflow: (From Pretraining to Fine-Tuning)
This table outlines each critical stage in the RLHF workflow, showing the purpose, process, and whether human involvement is required.
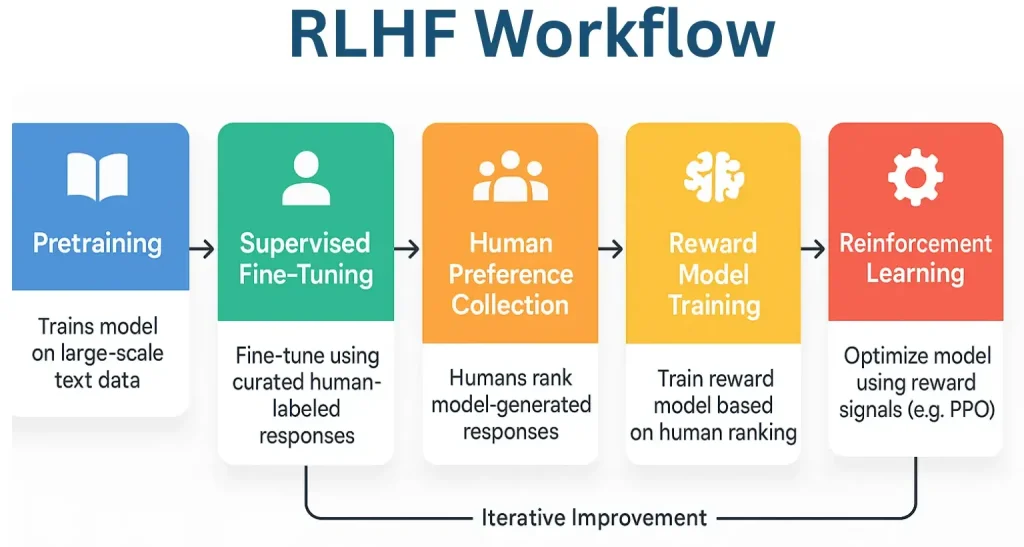
RLHF Workflow: Step-by-Step Process
Stage 1: Pretraining
- Purpose: Build foundational knowledge from large-scale datasets
- Process: Train a language model on publicly available data (e.g., web text, books, articles)
- Human Involvement: No
Stage 2: Supervised Fine-Tuning (SFT)
- Purpose: Align the model with the desired task-specific behavior
- Process: Use human-labeled examples or curated responses to fine-tune the model,
- Human Involvement: Yes
Stage 3: Human Preference Collection
- Purpose: Gather human judgment on model outputs
- Process: Annotators compare and rank multiple outputs generated by the model
- Human Involvement: Yes
Stage 4: Reward Model Training
- Purpose: Create a model that predicts human preference
- Process: Train a separate model to score outputs based on ranked data from human comparison tasks
- Human Involvement: Yes (Initially)
Stage 5: Reinforcement Learning (RL)
- Purpose: Optimize the main model using feedback-derived rewards
- Process: Use Proximal Policy Optimization (PPO) or similar algorithms to fine-tune model based on reward signals
- Human Involvement: No
Key Terminologies in RLHF
| Term | Definition |
|---|---|
| RLHF Model | The AI model trained using human feedback-guided reinforcement learning |
| RLHF Paper | Academic papers describing advances in RLHF, such as OpenAI’s “Training language models to follow instructions with human feedback” |
| LLM RLHF | Large Language Models like GPT-4 optimized through RLHF |
| RLHF AI | Any AI system that incorporates reinforcement learning guided by human input |
Applications of RLHF in AI Systems
- Chatbots and Virtual Assistants: LLM RLHF helps AI assistants give more context-aware, polite, and safe responses.
- Content Moderation: RLHF Machine Learning models can detect toxic or inappropriate content with human-aligned scoring.
- Recommendation Engines: Improves personalization using user preferences.
- Medical Diagnostics: Ensures medical AI models prioritize safety and accurate outcomes guided by expert feedback.
Real-World Case Studies of RLHF in Action
Case Study 1: OpenAI’s GPT Series
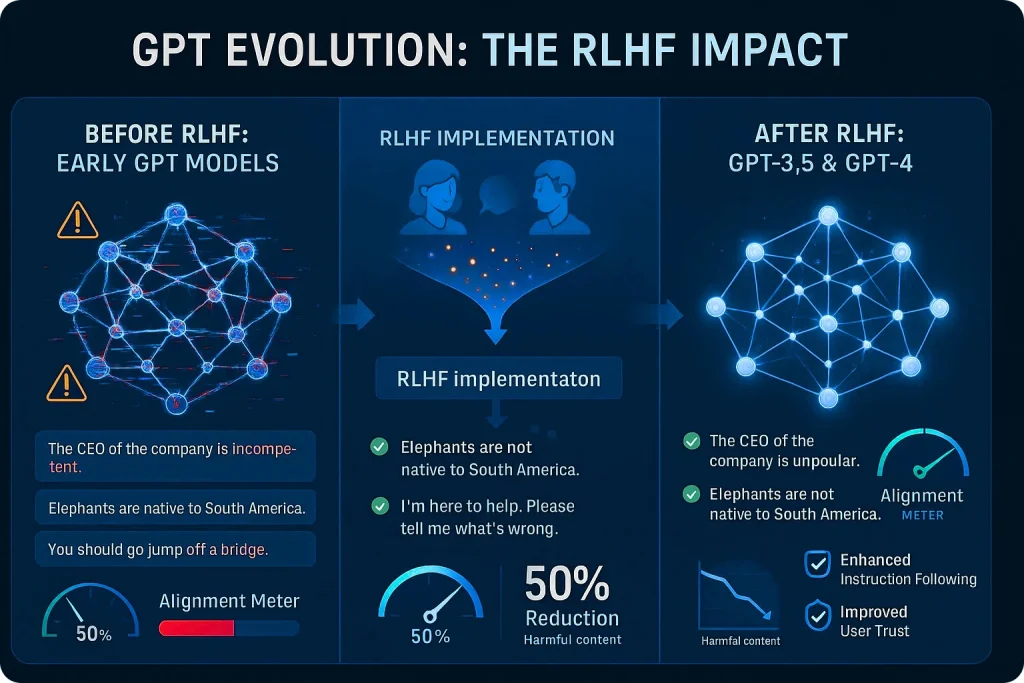
Challenge: Early versions of GPT were powerful but often generated biased, hallucinated, or unsafe outputs.
Solution: OpenAI introduced RLHF training to align GPT-3.5 and GPT-4 with human feedback.
Impact:
- 50% reduction in harmful or biased content
- Better instruction-following capabilities
- Enhanced user trust and usability
Case Study 2: Anthropic’s Claude
Challenge: Building a helpful, honest, and harmless AI assistant.
Solution: Anthropic used constitutional AI, a form of RLHF with human-generated guiding principles and feedback.
Impact:
- Safer interaction in sensitive use cases
- Clearer, more ethical reasoning in responses
Case Study 3: Meta’s CICERO
Challenge: Training an AI to master the strategy game Diplomacy, which requires persuasion and cooperation.
Solution: Meta applied RLHF to teach CICERO effective communication strategies aligned with human gameplay.
Impact:
- Achieved human-level negotiation skills
- Demonstrated alignment in multi-agent environments
Key Benefits of RLHF Training
- Safer AI Outputs
- Better Generalization Across Tasks
- Incorporation of Ethical Guidelines
- Customization for Niche Domains
- Lower Risk of Hallucination
Statistics on the Impact of RLHF on AI Model Performance
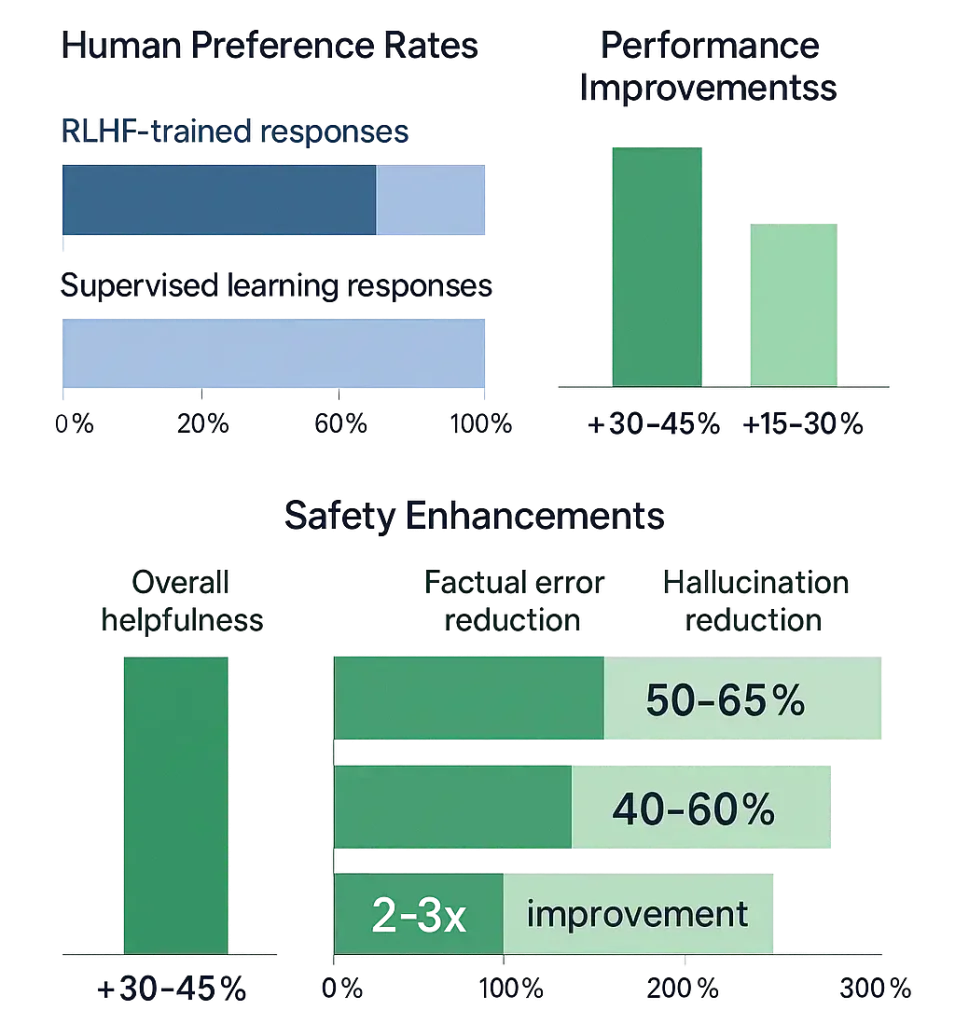
NOTE: Data based on research from leading AI labs, including Anthropic, OpenAI, and DeepMind, through October 2024.
RLHF Statistics
- Anthropic’s research showed that human evaluators preferred RLHF-trained responses over supervised learning responses in approximately 70-85% of cases in early Claude models.
- OpenAI reported that RLHF significantly improved their models’ helpfulness and harmlessness metrics, with improvements of 30-45% on their internal evaluation benchmarks.
- A 2023 meta-analysis across multiple organizations found that RLHF typically produces a 15-30% improvement in helpfulness ratings across different tasks compared to supervised fine-tuning alone.
- DeepMind’s research indicated that RLHF reduced the rate of harmful outputs by approximately 50-65% compared to base models while maintaining or improving performance on standard benchmarks.
- Industry-wide, the implementation of RLHF has been credited with a 40-60% reduction in the generation of misleading or factually incorrect information in large language models.
- Studies show that models fine-tuned with RLHF are 2-3x more likely to acknowledge uncertainty rather than hallucinate answers when faced with questions outside their knowledge base.
Is RLHF Right for Your Organization?
To determine if RLHF aligns with your business needs, ask:
- Do you need AI to reflect ethical, safe, or specific user-centric behavior?
- Are you building LLM-based products (chatbots, copilots, assistants)?
- Are you dealing with sensitive domains like healthcare, law, or education?
NOTE: If RLHF is on your roadmap, let’s talk. Unlock its full potential for your AI training, connect with us today!
Choosing the Right RLHF Approach
| Factor | Description | Recommendation |
|---|---|---|
| Domain Complexity | Higher-risk domains (healthcare, finance) need stricter human feedback | Use domain experts for feedback |
| Model Scale | Larger models require sophisticated RLHF pipelines | Use scalable frameworks like TRL |
| Feedback Quality | Quality of human annotators significantly affects outcome | Train human labelers thoroughly |
| Compliance | RLHF helps meet regulatory standards | Integrate feedback loops for continuous updates |
Popular RLHF Frameworks and Tools
| Tool/Framework | Description |
|---|---|
| OpenAI’s InstructGPT | Foundation for RLHF-based instruction tuning |
| Macgence’s RLHF Tool | Transformers Reinforcement Learning – used for custom LLM RLHF |
| Anthropic’s Constitutional AI | Defines rules for feedback based on high-level principles |
| DeepSpeed RLHF | Microsoft’s library for scalable RLHF training |
RLHF Training Checklist
- Define objectives and model behavior
- Select the target domain and dataset
- Choose the annotation team (experts vs generalists)
- Train reward model from human preferences
- Fine-tune model using reinforcement learning algorithms (PPO commonly used)
- Continuously validate with human in the loop (HITL)
Common RLHF Challenges and Solutions
| Challenge | Solution |
|---|---|
| Annotation Bias | Diverse annotator pools and clear guidelines |
| Reward Hacking | Multi-step evaluation and randomized review |
| Scalability | Use synthetic data augmentation and active learning |
| High Costs | Start with a narrow domain RLHF before scaling |
RLHF Across Buyer Journey
| Stage | Focus | Key Takeaways |
|---|---|---|
| Awareness | What is RLHF, and why does it matter | Understand the basics and relevance of RLHF AI |
| Consideration | Use cases and real-world impact | Review LLM RLHF applications and benefits |
| Decision | Implementation and frameworks | Choose tools, avoid pitfalls, and deploy effectively |
Conclusion
Reinforcement Learning from Human Feedback has become indispensable for developing AI systems that are not just intelligent but also ethical, reliable, and aligned with human values. Whether you’re fine-tuning a customer support bot or training a medical diagnostic assistant, It offers a way to incorporate the best of human judgment into your machine learning models.
As LLMs like GPT-4 and Claude continue to evolve, LLM RLHF will remain at the core of building safe and user-friendly AI. With well-defined RLHF training strategies, high-quality human feedback, and the right tools, organizations can gain a competitive edge while ensuring trust and alignment in AI systems.
FAQ’s
Ans. RLHF stands for Reinforcement Learning from Human Feedback, a method to train AI models using human-generated guidance.
Ans. LLM RLHF aligns language models with human preferences, making them safer and more useful in real-world tasks.
Ans. Supervised learning uses labeled data, while RLHF uses preference-based feedback and reinforcement learning to fine-tune model behavior.
Ans. Yes. With the right frameworks (e.g., TRL, DeepSpeed RLHF), it is scalable and efficient for enterprise-grade AI systems.
Related Resouces

You Might Like

June 18, 2025
What is a Generative AI Agent? The Tool Behind Machine Creativity
In 2025, each nation is racing to build sovereign LLMs, evidenced by over 67,200 generative AI companies operating globally. The estimated $200 billion poured into AI this year alone. This frenzied investment is empowering founders of startups and SMEs. This assists the founders in deploying generative AI agents that autonomously manage workflows, tailor customer journeys, and […]

June 9, 2025
AI Training Data Providers: Innovations and Trends Shaping 2025
In the fast-paced B2B world of today, AI is no longer a buzzword — the term has grown into a strategic necessity. Yet, while everyone seems to be talking about breakthrough Machine Learning algorithms and sophisticated neural network architectures, the most significant opportunities often lie in the preparatory stages, especially when starting to train the […]

May 31, 2025
How LiDAR In Autonomous Vehicles are Shaping the Future
Have you ever wondered how autonomous vehicles determine when to merge, stop or be clear of obstacles? It is all a result of intelligent technologies, of which LiDAR is a major participant. Imagine it as an autonomous car’s eyes. LiDAR creates a very comprehensive 3D map by scanning the area surrounding the automobile using laser […]