


NLP Data Annotation: The Foundation of Smarter Language Models
Natural Language Processing (NLP) has become a central part of modern AI. From chatbots and voice assistants to fraud detection and medical research, machines are expected to understand, interpret, and respond to human language. But for any NLP system to work, it needs carefully prepared training data. That’s where NLP data annotation comes in.
NLP data annotation is the process of labeling text so that machines can learn from examples and understand human language in context. Without it, even the most advanced machine learning models would struggle with ambiguity, slang, intent, and meaning.
In this article, we’ll break down what NLP data annotation is, why it matters, where it’s used, and the challenges and future trends shaping it.
What is NLP Data Annotation?
NLP data annotation is the practice of tagging or labeling text data to help machine learning algorithms recognize patterns and meaning in human language.
Some of the most common annotation types include:
- Text Classification: Assigning labels to entire documents or sentences, such as sentiment (positive, neutral, negative) or spam detection.
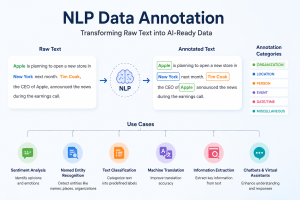
- Entity Annotation (NER): Highlighting and tagging entities like names, dates, organizations, and locations. Example: “Apple launched the iPhone in California” → [Apple: Organization], [California: Location].
- Part-of-Speech (POS) Tagging: Marking words as nouns, verbs, adjectives, etc., so models understand grammar and syntax.
- Semantic Annotation: Providing context or meaning to words or phrases. Example: tagging “Apple” as a company versus a fruit.
- Relationship Annotation: Linking entities together, such as identifying that a “patient” has a “diagnosis” or a “customer” bought a “product.”
By applying these labels, models gain the structured understanding needed to perform tasks like translation, summarization, and intent recognition.
Why NLP Data Annotation Matters
High-quality annotation is not optional. It directly impacts how accurate and useful an NLP model will be. Here’s why it matters:
- Improves Accuracy: Well-labeled data ensures the model learns correctly, reducing errors.
- Handles Ambiguity: Humans can resolve context, slang, or sarcasm that machines struggle with.
- Enables Real-World Applications: NLP models power systems we use daily, from search engines to healthcare AI.
- Supports Personalization: Annotated datasets help systems better understand intent and tailor experiences.
Simply put, annotation is the backbone of NLP. Without it, models would operate in the dark.
Where to Use NLP Data Annotation
NLP data annotation has applications across industries. Some key use cases include:
- Customer Service: Training chatbots and virtual assistants to recognize intent, sentiment, and common support queries.
- Healthcare: Annotating clinical notes, patient records, and medical literature for diagnosis support, drug discovery, and research.
- Finance: Categorizing customer queries, detecting fraudulent transactions, and analyzing financial reports.
- E-commerce: Product categorization, personalized recommendations, and sentiment analysis of customer reviews.
- Legal & Compliance: Annotating contracts, case documents, and regulatory filings for faster legal research and compliance monitoring.
- Search Engines & Voice Assistants: Improving how queries are interpreted, enabling accurate voice-to-text conversions, and refining results.
Wherever text data exists, NLP data annotation makes it usable for AI systems.
How NLP Data Annotation Works
The annotation process usually follows a structured workflow:
- Data Collection – Gathering raw text from sources like chat logs, documents, or customer reviews.
- Annotation – Human annotators (sometimes assisted by AI tools) label the data according to project needs.
- Quality Assurance – Reviewing labels to ensure consistency and accuracy across the dataset.
- Integration – Feeding the annotated data into machine learning pipelines to train or fine-tune models.
Depending on the scale and complexity, annotation may be:
- Manual (entirely human-driven) for high accuracy.
- Semi-Automated with AI-assisted tools where humans validate suggestions.
- Fully Automated for repetitive tasks, though human oversight is often needed.
Challenges in NLP Data Annotation
While powerful, NLP annotation is not without challenges:
- Subjectivity: Sentiment or intent can vary depending on cultural and personal context.
- Scalability: Large datasets require significant time and resources.
- Consistency: Multiple annotators may interpret the same text differently, leading to bias.
- Privacy Concerns: Handling sensitive text data in industries like healthcare and finance demands strict compliance with data security standards.
Overcoming these challenges often requires clear annotation guidelines, quality checks, and the use of Human-in-the-Loop (HITL) systems to balance efficiency and accuracy.
NLP Data Annotation Services by Macgence AI
At Macgence, we provide end-to-end NLP data annotation services designed to help organizations build accurate and scalable AI models. Our services cover the full spectrum of NLP requirements, ensuring high-quality labeled datasets tailored to industry-specific needs.
Our Core NLP Data Annotation Services
- Text Classification: Categorizing documents, reviews, or messages into predefined classes such as sentiment, intent, or spam detection.
- Named Entity Recognition (NER): Annotating entities like names, organizations, locations, dates, and product references to train models for search, chatbots, or analytics.
- Part-of-Speech (POS) Tagging: Identifying nouns, verbs, adjectives, and other grammatical categories to support syntactic parsing and machine translation.
- Semantic Annotation: Adding contextual meaning to words and phrases, such as distinguishing between homonyms (e.g., “bank” as a financial institution vs. “bank” of a river).
- Relationship Annotation: Linking entities and concepts (e.g., patient–disease, customer–product) for advanced NLP tasks like knowledge graph building.
- Sentiment & Intent Annotation: Labeling text to capture emotions, attitudes, and intent, critical for customer service automation, brand monitoring, and personalization.
Why Businesses Choose Macgence
- Industry Expertise – Specialized annotators in healthcare, finance, legal, e-commerce, and other domains.
- Scalable Workforce – Ability to handle projects of any size, from pilot datasets to enterprise-level volumes.
- Human-in-the-Loop Approach – AI-assisted annotation combined with human validation for the highest accuracy.
- Data Security & Compliance – Strict protocols to safeguard sensitive and confidential data.
- Custom Solutions – Tailored annotation strategies aligned with your project goals and AI development roadmap.
With Macgence as your partner, you gain not just labeled data but strategic NLP training datasets that drive reliable, real-world AI performance.
The Future of NLP Data Annotation
As NLP evolves, so does annotation. Key trends include:
- AI-Assisted Annotation: Tools that speed up labeling by suggesting tags, with humans refining the results.
- Domain-Specific Datasets: Specialized annotations for healthcare, law, or finance, which require subject matter expertise.
- Multilingual Annotation: Expanding to global languages and dialects for more inclusive AI systems.
- Ethical Annotation Practices: Addressing bias and ensuring fairness in datasets to avoid reinforcing stereotypes.
In short, the future lies in smarter, faster, and more ethical annotation practices.
Conclusion
NLP data annotation is the unsung hero of modern AI. By carefully labeling text, we enable machines to understand language with accuracy and context. Whether it’s powering chatbots, streamlining healthcare, or improving search engines, annotation is the foundation.
Organizations that invest in high-quality, ethical annotation practices will build NLP models that are not just smarter but also more reliable and user-friendly.
FAQ’s
NLP data annotation is the process of labeling text data so that machine learning models can understand human language, intent, and context.
Without annotation, NLP models cannot interpret meaning or context. Quality annotation ensures accuracy, reduces errors, and enables real-world applications.
Industries such as healthcare, finance, legal, e-commerce, and customer service rely heavily on annotated text to build reliable AI solutions.
Macgence uses a Human-in-the-Loop (HITL) approach, combining automation with expert human validation, along with strict quality checks and compliance standards.
Yes. With a scalable workforce and efficient workflows, Macgence supports both small pilot datasets and large enterprise projects.
 Previous Blog
Previous Blog



You Might Like

June 18, 2026
Mastering Teleoperation Data Annotation for Robotics
The demand for intelligent robotics and autonomous systems is accelerating at an unprecedented rate. As machines take on increasingly complex tasks, developers face a significant hurdle: teaching robots how to navigate the unpredictable nature of real-world environments. Teleoperation bridges the gap between human intelligence and machine learning by allowing humans to guide robots through specific […]

June 17, 2026
Choosing the Right Image Annotation Companies for AI Growth
Behind every successful computer vision model is an enormous volume of high-quality labeled data. AI systems depend entirely on this foundational layer to understand, interpret, and react to the visual world. Image annotation serves as the bedrock of computer vision. Without it, the sophisticated algorithms powering modern technology simply cannot function. Countless industries rely heavily […]

June 15, 2026
Why Teleoperation Data Collection Is Critical for AI-Powered Robotics?
Teleoperation lets a human operator remotely control a robot, drone, or vehicle from a distance, often using cameras, sensors, and a control interface. As robotics and autonomous systems move from labs into warehouses, farms, and city streets, they need vast amounts of real-world operational data to learn from. That’s where teleoperation data collection comes in. […]