

- What Is Egocentric Video Annotation?
- Why Egocentric Video Annotation Matters for AI Development
- Key Use Cases of Egocentric Video Annotation
- Types of Annotations Used in Egocentric Video Projects
- Unique Challenges in Egocentric Video Annotation
- Best Practices for High-Quality Egocentric Video Annotation
- How Macgence Delivers Accurate Egocentric Video Annotation Services
- Future Trends in Egocentric Video Annotation
- Transforming the Future of AI with Better Data
- FAQs
Egocentric Video Annotation: Powering Embodied AI
The demand for embodied AI and robot learning is growing rapidly. Developers are shifting their focus from AI that simply observes the world to systems that actively interact with it. To achieve this, models need a different kind of training data. They need to see the world exactly as we do.
Traditional third-person video datasets have driven significant breakthroughs in computer vision. However, these exocentric perspectives are often insufficient for understanding complex human interactions. They lack the fine-grained details of how a person grasps an object, navigates a cluttered room, or shifts their gaze during a task.
This is where egocentric video annotation becomes essential. By labeling data captured from a first-person perspective, computer vision teams can build powerful models for robotics, imitation learning, activity recognition, and multimodal AI systems. Macgence specializes in annotating these complex AI training datasets, delivering the precise, high-quality labeling required to push the boundaries of modern AI.
What Is Egocentric Video Annotation?
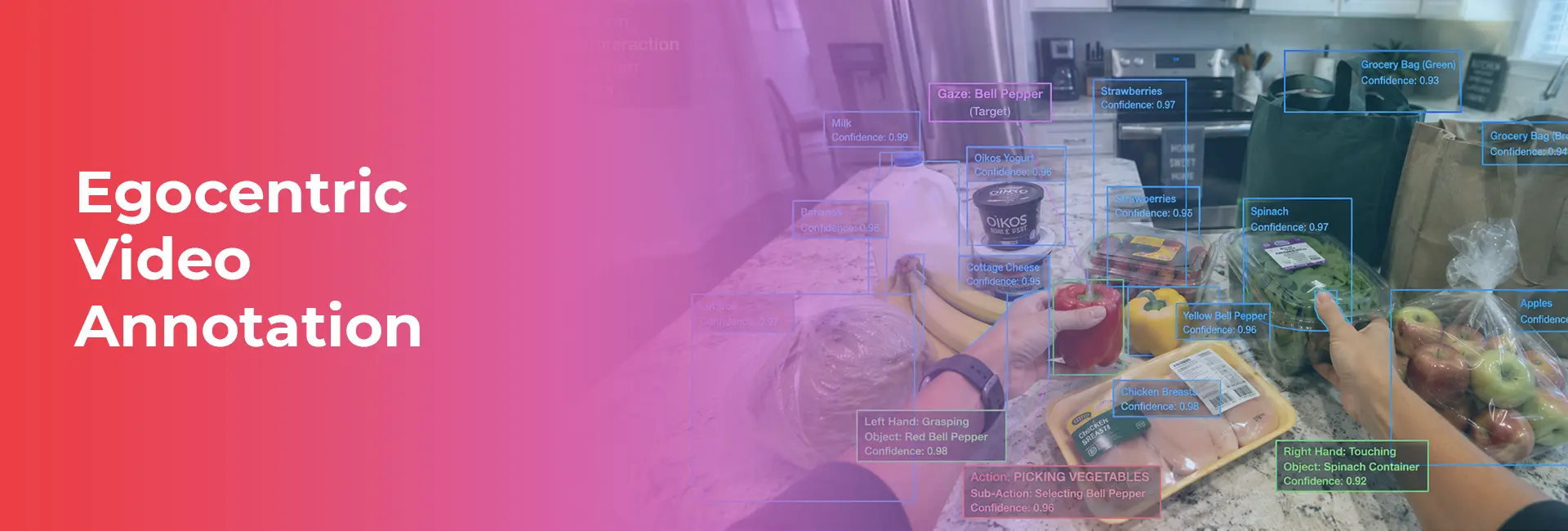
Egocentric video annotation involves labeling video data captured from a first-person point of view (POV). Unlike exocentric annotation, which relies on fixed cameras like CCTVs observing a scene from a distance, egocentric data is recorded using wearable cameras, smart glasses, head-mounted devices, or robot-mounted sensors.
This perspective provides a highly detailed view of the camera wearer’s immediate environment and interactions. To make sense of this data, human annotators must label several complex elements:
- Object annotation: Identifying tools, ingredients, or obstacles in the wearer’s immediate vicinity.
- Hand-object interaction labeling: Tracking exactly how hands manipulate specific items.
- Action recognition tagging: Classifying specific tasks, such as chopping vegetables or typing on a keyboard.
- Gaze estimation support: Noting where the wearer is looking during a task.
- Human pose annotation: Estimating the body mechanics of the person wearing the camera.
- Scene understanding: Categorizing the broader environment.
- Temporal event segmentation: Marking the exact start and end times of continuous actions.
Why Egocentric Video Annotation Matters for AI Development
First-person data provides a unique advantage for training intelligent systems. It offers deep contextual clues that third-person cameras simply cannot capture.
Enabling Human-Like Understanding
Egocentric video annotation teaches AI systems how humans interact with their environments. By analyzing these videos, machine learning models learn the sequence of actions required to complete a task. They begin to understand the intent behind an action and the context in which it occurs.
Improving Real-World Decision Making
When a model understands object manipulation from a first-person view, it can make better decisions in real-world environments. This data enables context-aware navigation, helping AI predict what actions are likely to happen next through activity forecasting.
Supporting Embodied AI Systems
Embodied AI requires systems to learn through human demonstrations. Egocentric data enhances the perception capabilities of humanoid robots. It allows these physical systems to adapt to dynamic environments by mimicking the ways humans navigate unpredictable spaces.
Key Use Cases of Egocentric Video Annotation
First-person video datasets support a wide variety of advanced technology applications across multiple industries.
Robotics and Learning from Demonstration (LfD)
Robots learn complex tasks by observing human behavior. Egocentric video annotation helps these machines understand manipulation trajectories and model the exact physical execution of a task.
Human Activity Recognition
From cooking activities and household chores to complex industrial workflows and retail operations, first-person data helps AI categorize and monitor human activities with incredible precision.
Autonomous Systems
Egocentric data improves navigation assistance systems and fosters safer human-robot collaboration. Context-aware AI agents rely on this information to understand their immediate surroundings.
AR/VR and Wearable AI
Augmented and virtual reality rely heavily on gesture recognition and user behavior understanding. First-person annotation helps build more responsive and immersive environment interactions.
Healthcare and Rehabilitation
Medical professionals use egocentric AI systems to monitor patient activities, assess physical therapy progress, and develop non-intrusive elderly care applications.
Types of Annotations Used in Egocentric Video Projects
Annotating first-person video requires a diverse toolkit of labeling techniques to capture all necessary environmental details.
- Bounding Box Annotation: This technique provides simple object localization within video frames.
- Polygon Annotation: Annotators use polygons for precise object boundary labeling, which is crucial for complex object interactions.
- Keypoint Annotation: This is used for detailed hand tracking, finger movement analysis, and pose estimation support.
- Semantic Segmentation: This offers pixel-level scene understanding by classifying every pixel in a frame.
- Instance Segmentation: This technique distinguishes between multiple objects of the same category, such as identifying three separate coffee cups on a desk.
- Temporal Annotation: Annotators mark action start and end points for precise event segmentation.
- Activity Classification: This involves labeling complete task sequences to categorize the overall behavior.
Unique Challenges in Egocentric Video Annotation
First-person video presents distinct hurdles that third-person data usually avoids.
Because the camera is attached to a moving person or robot, frequent camera motion causes severe motion blur and rapid scene transitions. Additionally, objects are frequently obscured by the wearer’s hands. These occlusions make complex object manipulation sequences difficult to track.
Long video durations create large-scale annotation requirements, making it tough to maintain consistency across thousands of frames. Annotators must also possess complex contextual understanding to identify subtle human actions and multi-step task recognition. Managing millions of frames efficiently requires immense annotation scalability.
Best Practices for High-Quality Egocentric Video Annotation

To overcome these challenges, data science teams must follow rigorous operational standards.
Define Clear Annotation Guidelines
Projects require standardized labeling protocols. Clear rules ensure consistency across large annotation teams, preventing conflicting data labels.
Use Multi-Level Quality Assurance
A robust pipeline includes initial annotation, followed by expert review, and culminating in final validation. This catches errors early in the process.
Leverage Domain-Specific Annotators
Certain projects require specialized knowledge. Utilizing robotics experts, healthcare specialists, or industrial workflow annotators ensures that the labels accurately reflect the highly technical tasks being performed.
Maintain Temporal Consistency
Teams must verify frame-to-frame annotation accuracy and event continuity. An object labeled in one frame must retain its identity throughout the entire interaction sequence.
Incorporate Human-in-the-Loop Validation
Automated pre-labeling tools speed up the process, but combining automation with expert human review guarantees the high accuracy needed for critical AI applications.
How Macgence Delivers Accurate Egocentric Video Annotation Services
Macgence provides the infrastructure, workforce, and security required to handle complex first-person video datasets.
We utilize specialized annotation workflows with customized project pipelines and domain-specific protocols. Our teams excel at supporting advanced robotics data, delivering precise labels for hand-object interactions, manipulation tasks, and activity recognition.
We offer scalable annotation operations capable of large-volume video processing and multi-stage quality control. Beyond video, our multimodal annotation expertise extends to image, audio, and sensor fusion datasets. All of this is backed by enterprise-grade data security, ensuring secure handling of sensitive datasets and compliance-focused processes.
Future Trends in Egocentric Video Annotation
The demand for high-quality first-person data will only increase as the AI industry advances.
Foundation models for robotics are driving a massive need for large-scale first-person datasets. Developers are also focusing on Vision-Language-Action (VLA) models, which directly link visual perception with physical robot actions.
We will see deeper integration of multimodal learning, combining video, audio, depth, and sensor data. As humanoid robotics advance, training these machines using real-world human demonstrations will become standard practice. Ultimately, real-time annotation and data enrichment will enable faster model iteration cycles.
Transforming the Future of AI with Better Data
Egocentric video annotation is a foundational requirement for the next generation of artificial intelligence. Its role in robotics, embodied AI, activity recognition, and autonomous systems cannot be overstated. High-quality annotations directly dictate model performance and reliability in the real world.
Macgence helps organizations build reliable AI systems through scalable and accurate egocentric video annotation services. By partnering with experts who understand the nuances of first-person data, your team can accelerate development and deploy models with confidence.
FAQs
Ans: – Egocentric video annotation is the process of labeling video footage captured from a first-person perspective, typically using wearable cameras. It involves tagging objects, hands, actions, and environments to train AI models.
Ans: – Traditional video annotation relies on static, third-person cameras observing a scene. Egocentric annotation uses first-person footage, capturing rapid camera movements, direct hand-object interactions, and the wearer’s specific point of view.
Ans: – This type of annotation is widely used in robotics, healthcare, augmented and virtual reality, autonomous systems, manufacturing, and retail.
Ans: – Common types include bounding boxes, polygons, keypoint tracking (for hands and poses), semantic and instance segmentation, and temporal annotation for action segmentation.
Ans: – It allows robots to learn from human demonstration. By analyzing first-person footage, robots can understand intent, grasp mechanics, and context-aware navigation.
Ans: – Key challenges include severe motion blur, rapid scene changes, frequent occlusions caused by the wearer’s hands, and the need to maintain temporal consistency across long video sequences.
Ans: – Macgence uses multi-level quality assurance, domain-specific experts, strict annotation guidelines, and a human-in-the-loop validation process to maintain high accuracy and temporal consistency.
Ans: – Yes. By providing detailed visual context linked to specific physical actions, egocentric data is crucial for training VLA models that connect visual inputs with language commands and robotic execution.
 Previous Blog
Previous Blog



You Might Like

June 18, 2026
Mastering Teleoperation Data Annotation for Robotics
The demand for intelligent robotics and autonomous systems is accelerating at an unprecedented rate. As machines take on increasingly complex tasks, developers face a significant hurdle: teaching robots how to navigate the unpredictable nature of real-world environments. Teleoperation bridges the gap between human intelligence and machine learning by allowing humans to guide robots through specific […]

June 17, 2026
Choosing the Right Image Annotation Companies for AI Growth
Behind every successful computer vision model is an enormous volume of high-quality labeled data. AI systems depend entirely on this foundational layer to understand, interpret, and react to the visual world. Image annotation serves as the bedrock of computer vision. Without it, the sophisticated algorithms powering modern technology simply cannot function. Countless industries rely heavily […]

June 15, 2026
Why Teleoperation Data Collection Is Critical for AI-Powered Robotics?
Teleoperation lets a human operator remotely control a robot, drone, or vehicle from a distance, often using cameras, sensors, and a control interface. As robotics and autonomous systems move from labs into warehouses, farms, and city streets, they need vast amounts of real-world operational data to learn from. That’s where teleoperation data collection comes in. […]