


- What is Autonomous Data Annotation?
- Why Autonomous Data Annotation is Critical for Autonomous Vehicles
- Techniques Used in Data Annotation for Autonomous Vehicles
- Comparison Table
- Autonomous Data Annotation Challenges
- Best Practices for Effective Data Annotation
- Tools and Solutions for Data Annotation
- Macgence’s Value Proposition
- Future Trends in Data Annotation for Autonomous Vehicles
- Conclusion
- FAQs
- References
What is Autonomous Data Annotation and Why Your Business Needs It
Imagine a world in which intelligent systems that are never bored or distracted cause traffic to flow smoothly, packages arrive at your door without a human driver, and automobiles drive themselves. That future is not far off, and it is being facilitated by strong artificial intelligence (AI) and autonomous vehicles (AVs), which are already beginning to change the way we move objects and travel.
The problem is that these cars must be able to perceive and comprehend their surroundings, just like a person, in order to drive safely and make wise judgments. This type of intelligence, from identifying a person to seeing a stop sign, is not something that just happens. In order to educate AI on how to act, it begins with data—and not just any data, but high-quality, labeled data.
Autonomous data annotation is useful in this situation. It’s a backend procedure that helps AI systems learn more quickly and effectively by automatically categorizing and classifying the data they require. Consider it as providing the AI with a clear set of instructions so it may confidently explore the actual world.
In this article, we’ll explain autonomous data annotation, including its definition, operation, significance for AVs, difficulties, and optimal practices. Hold on tight, as we examine the technology that is shaping the future in further detail.
What is Autonomous Data Annotation?
The process of labeling or tagging various data formats, such as photos, videos, LiDAR scans, and radar signals, so that machine learning models can understand them is known as autonomous data annotation. Consider it as a way to train an AI system to “see” the world by providing it with examples and detailed explanations.
This is a very necessary step for driverless cars. AI is used by these cars to comprehend their environment and make safe judgments while driving. However, the AI needs very accurately labeled data to identify, as it cannot learn on its own.
Imagine a self-driving automobile is speeding along a very high-traffic downtown street. For it to navigate properly, it has to be able to distinguish between different traffic signs. These things are clearly indicated in the photographs and videos that are used to train the AI using annotated data.
A few instances of what may be annotated in scenarios of urban driving are as follows:
- People walking—so the car knows when to slow down or stop.
- To prevent crashes and keep a safe distance from other cars.
- Traffic lights: heed the warnings and regulations.
- Road signs should be followed to stay on the right path and adhere to speed restrictions.
Why Autonomous Data Annotation is Critical for Autonomous Vehicles
The following explains the importance of autonomous data annotation:
Aids AI in Making Smart Decisions
- Annotated data is used by AI algorithms to understand how to respond to various scenarios.
Prepares for All Kinds of Conditions
- Trains AVs to perform in urban areas, highways, and rural roads.
- Annotated data includes scenarios like:
- Rainy, foggy, or snowy weather
- Nighttime and low-light conditions
- Busy intersections or construction zones
Covers Real-World and Edge Cases
- AI learns from rare but critical situations (e.g., kids running into the street, animals crossing, sudden lane closures).
- Helps improve the system’s ability to handle unexpected challenges.
Improves Recognition Capabilities
- Obstacle detection: cars, bikes, potholes, animals, etc.
- Lane detection: helps keep the vehicle centered and safe.
- Traffic signs and lights: teaches the AV to obey rules and signals.
Powers Better Decision-Making
- The more varied and accurate the annotations, the smarter the AI becomes.
- Leads to safer behavior in unfamiliar or complex scenarios.
Supports Higher Levels of Autonomy (Level 3+)
- Level 3 and above require vehicles to operate with minimal or no human help.
- This level of autonomy depends on highly trained AI—powered by well-annotated, diverse datasets.
Techniques Used in Data Annotation for Autonomous Vehicles
Depending on the kind of data and the complexity of the environment, several annotation approaches are employed to train machine learning models used in autonomous cars. Each method contributes in a different way to the AI’s ability to precisely “see” and comprehend its environment.
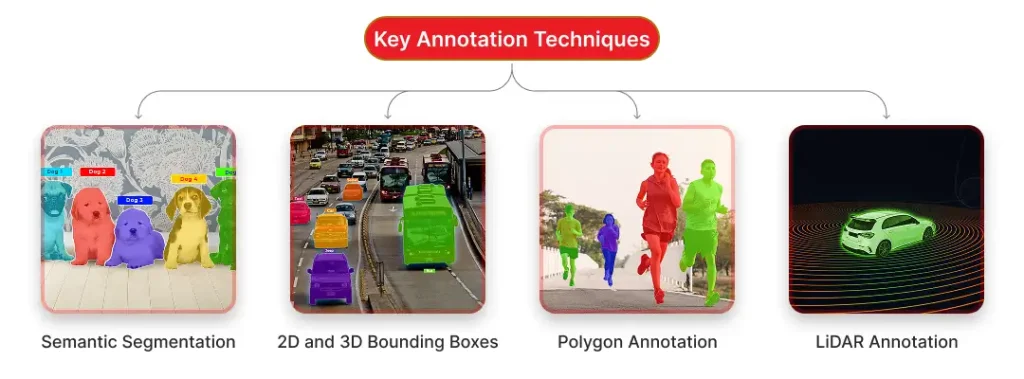
1. Semantic Segmentation
- Each pixel in an image is labeled with a category (like road, car, pedestrian, etc.).
- Helps the model understand the exact shape and boundary of every object.
- Used for detailed scene understanding.
2. 2D and 3D Bounding Boxes
- Boxes are drawn around objects in images or point clouds to indicate their presence.
- 2D boxes are for flat images, while 3D boxes capture depth and position in real-world space.
- Useful for identifying vehicles, pedestrians, traffic signs, etc.
3. Polygon Annotation
- Used to mark objects with irregular or complex shapes by outlining them with multiple points.
- Offers more precision than rectangular boxes.
- Commonly used for bikes, pedestrians, animals, or any non-boxy object.
4. LiDAR Annotation
- Labels 3D point cloud data collected from LiDAR sensors.
- Essential for depth estimation, object detection, and tracking in 3D space.
- Helps the vehicle understand distances and object movement.
Comparison Table
| Annotation Technique | Use-Case | Benefits | Limitations |
Semantic Segmentation | Scene understanding in complex areas | High accuracy for object shapes and borders | Computationally intensive, time-consuming |
| 2D Bounding Boxes | Image-based object detection | Simple, fast, widely used | Lacks depth and precise object boundaries |
| 3D Bounding Boxes | Depth-aware object tracking | Enables spatial awareness and distance tracking | Requires LiDAR data, more complex setup |
| Polygon Annotation | Irregular object labeling | More accurate for complex shapes | Manual effort is higher |
| LiDAR Annotation | 3D object detection and mapping | Precise depth perception and motion analysis | Requires specialized tools and expertise |
Autonomous Data Annotation Challenges
Accurately categorizing items is only one aspect of autonomous data annotation; another is doing so in an environment where many factors are unexpected. The following are the main obstacles that make this task both crucial and difficult:
Urban Environments:
Due to their density and dynamic nature, cities provide a significant challenge for annotation. Labelers have to cope with things that overlap, such as a bike cycling next to a bus or a pedestrian crossing in front of a parked automobile. To guarantee that the AI can accurately comprehend each item and its activity, these overlapping and continuously changing pieces need to be extremely detailed.
Weather and Lighting Variability:
From dazzling sunshine to pitch-black at night, lighting conditions vary greatly. When you combine weather conditions like fog, rain, and snow, you may get pictures with important details hidden or warped. For example, snow may obscure lane lines, while a damp road may reflect traffic signals. These variances necessitate specialized and subtle annotation procedures that can manage data with minimal visibility.
Edge Cases & Unusual Occurrences:
Not every driving situation is the same. Additionally, autonomous vehicles need to be educated to manage uncommon but crucial scenarios like construction sites, traffic jams, unexpected human movements, or wildlife crossing a rural route. It’s challenging to collect enough instances for machine learning because these occurrences are rare.
Need for Human and Automated Collaboration:
Relying exclusively on people or robots is insufficient due to the volume and complexity of data. Although automated systems are capable of doing repetitive operations at a large scale, they cannot pick up on subtleties in difficult circumstances. Particularly in edge circumstances, human annotators provide the contextual knowledge required to clear up ambiguity. To guarantee accuracy and consistency across datasets, the best method is a human-in-the-loop system in which automation is directed by expert assessment.
Best Practices for Effective Data Annotation

Best practices must be followed while annotating datasets to guarantee that autonomous cars learn from accurate and significant data.
Establish Clear Guidelines for Annotation:
The annotating team should have clear and comprehensive guidelines before beginning any assignment. These rules ought to include object definitions, labeling protocols, edge situations, occlusion management, and particular instructions for every kind of data, including pictures, LiDAR scans, and videos. This reduces ambiguity and guarantees that every annotator is using the same methodology.
Train Human Annotators and Use a Review Pipeline:
Human annotators are essential, particularly when handling complicated or unclear scenarios. Maintaining quality is aided by spending time teaching them on both tools and annotation standards. An additional layer of accuracy and early mistake detection is provided by a multi-step review process in which one or more reviewers examine annotations.
Employ Automation with Human Oversight:
When it comes to enormous datasets, automated methods may greatly expedite the annotation process. Basic chores may be handled effectively with methods like auto-segmentation and pre-labeling. To improve and confirm results, these technologies should be used in conjunction with human oversight, especially in complex or uncertain situations.
Diversify the Dataset:
A well-rounded training dataset that is well-rounded should represent the whole spectrum of potential settings that an autonomous car could come across. Day and nighttime scenes, various weather patterns (rain, fog, snow), several kinds of roads (country, urban, and highway), and various geographic regions are all included in this. Incorporating edge cases and uncommon events is crucial for AI model development. Specifically, this inclusion contributes to the creation of more robust models. Consequently, these enhanced models can function more dependably in practical settings.
Tools and Solutions for Data Annotation
- Popular Annotation Tools:
Strong features for annotating photos and LiDAR data are provided by platforms such as CVAT, Labelbox, and SuperAnnotate. They support a variety of approaches, including bounding boxes and semantic segmentation. - AI-Powered Automation:
Many tools now incorporate machine learning to pre-label data, reducing manual effort. Automation accelerates large-scale annotation while lowering costs. - Role of Companies like Macgence:
Macgence provides end-to-end data annotation services, combining automation with skilled human annotators to ensure accuracy and consistency.
Macgence’s Value Proposition
- Offers accurate, efficient, and scalable data annotation services.
- Supports diverse datasets including images, videos, LiDAR, and radar.
Designed to help AI/ML teams train high-performing models for autonomous vehicles and beyond.
Future Trends in Data Annotation for Autonomous Vehicles
Artificial Intelligence-Driven Annotation:
Looking ahead, future annotation solutions will increasingly employ pre-trained AI models in order to automate labeling activities with more accuracy and less human involvement.
Synthetic Data:
When real-world data gathering is scarce for uncommon or hazardous situations, such as accidents or severe weather, simulated environments can assist in producing labeled data.
Changing Regulations:
International regulatory organizations are attempting to impose more stringent requirements on data quality, particularly for AI applications that are vital to safety or autonomous driving.
Prospects: Achieving Level 5 Autonomy
Achieving Level 5 autonomy, which would enable automobiles to operate in any circumstance without human assistance, will require annotation. It will take high-quality, diverse, and intelligently labeled data to accomplish this aim safely and efficiently.
Conclusion
Data annotation is an essential component of safe and effective self-driving cars in the drive toward complete autonomy. Accurately categorized data assists AI in making more intelligent judgments when driving, from identifying road signs to comprehending intricate urban surroundings. Even while problems like unpredictable weather and uncommon occurrences still exist, they may be resolved with the correct combination of automation, human skill, and dependable equipment. Businesses that want to be at the forefront of this field need to make investments in superior annotation techniques. Given its accurate and scalable solutions, Macgence enables businesses to remain ahead of the curve in the rapidly changing field of autonomous mobility. Consequently, it helps them expedite AI development.
FAQs
Ans: – Radar data, LiDAR point clouds, images, and videos are frequently annotated for training.
Ans: – Accurate data annotation is challenging, particularly in complicated contexts. Furthermore, edge situations present significant hurdles. Finally, inconsistent labeling adds another layer of difficulty to the process.
Ans: – In order to assist cars comprehend the precise forms and positions of objects, it identifies each pixel in a picture.
Ans: – Several annotation formats are supported by programs such as CVAT, Labelbox, and SuperAnnotate.
Ans: – Maintain clear criteria, use AI-assisted tools, and carry out frequent quality checks.
Ans: – ML models, particularly for huge datasets, help in auto-labeling and minimize manual labor.
References
- https://macgence.com/blog/a-brief-guide-about-the-data-annotation/
- https://macgence.com/blog/a-comprehensive-guide-to-data-annotation/
- https://ml.techasoft.com/post/how-data-annotation-is-revolutionizing-autonomous-vehicles
- https://www.basic.ai/blog-post/data-annotation-for-autonomous-driving
- https://www.anolytics.ai/blog/role-of-data-annotation-in-driving-ai-success-across-industries/

You Might Like

October 11, 2025
Why Your AI Can’t Understand Humans: The Multimodal Conversations Datasets Gap
Your conversational AI is failing, and you probably don’t know why. It responds to words perfectly. The grammar checks out. The speed is impressive. But somehow, it keeps missing what users actually mean. The frustrated customers. The sarcastic feedback. The urgent requests are buried in casual language. Here’s what’s really happening: your AI is reading […]

October 10, 2025
Why Your Self-Driving Car Needs Perfect Vision: The LiDAR Annotation Story
Imagine you’re driving down a busy street. Your eyes are constantly scanning – pedestrians crossing, cars merging, cyclists weaving through traffic. Now imagine teaching a machine to do the same thing, except it doesn’t have eyes. It has lasers. And those lasers need to understand what they’re “seeing.” We’ve seen many product launches that aim […]

October 9, 2025
What is Synthetic Datasets? Is it real data or fake?
Picture this: You’re building the next breakthrough AI product. Your models need millions of data points to learn. But there’s a problem. You can’t access enough real-world data due to various factors, such as compliance issues, security factors, and specific needs. Privacy regulations block you. Collection costs are sky-high. And even when you get data, […]