


What Goes Into Building a Conversational AI Dataset: A Deep Dive
The factor that distinguishes a successful conversational AI from an unsuccessful one is the dataset. While ML practitioners focus more on the model architectures and optimization techniques. The quality of the training data has the same importance as equivalent to model design and implementation. Whether your chatbot texts out meaningful conversations or exasperating interactions.
Building the datasets will be the foundation in developing robust and reliable conversational AI systems. Each kind of modality will have some of its own unique issues and challenges. The conversational dataset should have various factors representing the natural flow of human dialogues and contextual awareness. With some apt captures for subtle rhythms of turn-taking existent in natural communication.
A big concern arises when it comes to the quality of datasets since these conversational AI systems deal with queries directly with a user. Thereby making anything from the dataset apparent in production.
The entire guide goes on to discuss the whole pipeline for the creation of your conversational AI datasets. Answer your question: does it fit for my production?
Conversational AI Dataset Requirements
Conversational AI datasets are different from traditional machine learning datasets. The reason for this is their deeper structural complexity and unique annotation demands. Unlike traditional datasets that often contain isolated, single-label examples, conversational data reflects multi-turn dialogues filled with shifting context and meaning.
Because of this, modern AI systems must learn from datasets that support several understanding tasks all at once—without losing consistency. In one interaction, a model may need to perform intent classification, entity recognition, sentiment analysis, and track the dialogue state.
Therefore, the dataset must handle multi-layered labels in parallel, ensuring coherence across each layer despite the evolving nature of conversation. Moreover, the temporal flow of dialogue adds another layer of complexity—each utterance depends heavily on what came before.
This dependency means that conversational datasets must preserve context across turns, which static datasets rarely account for effectively. According to research by Stanford’s Human-Computer Interaction Lab, context carryover can impact model understanding by up to 34%.
Not to mention, these datasets must contain substantial linguistic diversity. Beyond vocabulary-and speaking to communicating styles as well as tones and different degrees of formality. It also need to take into account regional dialects and cultural underpinnings to facilitate the AI systems.
Only with this richness and attention to detail can a conversational AI system feel responsive, inclusive, and truly human-aware.
Data Collection Strategies and Sources
Primary Data Collection Methods
Human-to-Human Conversations
Customer service logs are some of the most precious resources for building conversational AI datasets. These interactions usually show the very nature of goal-oriented dialogue with natural language templates and flows toward solutions. Yet the regulatory restrictions on privacy and the requirements for consent by customers restrict a direct view of this data.
Social media interactions and forum discussions constitute one other profuse source of conversational data. Internet communities on Reddit, Discord, and specialized forums create millions of natural conversations every day. Intuitively, to extract structured dialogues from these unstructured ones is an unimaginably complex preprocessing task. Which involves the identification of conversation threads and participant personas.
Crowdsourcing-based conversation generation offers a more controlled alternative for data collection. Services including Mechanical Turk and specialized platforms give researchers the ability to commission conversations of particular type. While this affords somewhat greater control over what the conversations will concern as well as quality. It may restrict the spontaneity that accompanies organic interactions.
Wizard-of-Oz studies represent a methodical approach to controlled data collection. In these studies, human operators simulate AI responses while participants believe they’re interacting with automated systems. This methodology generates high-quality training data while allowing researchers to explore specific conversation patterns and user behaviors.
Human-to-Bot Interactions
This conversation-based data may help realize behaviors and commonplace interaction types isolated to actual users. In addition, logs can show real user engagement with conversational systems such as language choices, expectations, or expressions of frustration. However, initial interactions in early-stage bots contain a lot of noise and are not even exemplary conversation flows.
Beta testing programs offer structured opportunities to collect user interactions with controlled system variations. These programs enable researchers to gather feedback on conversational designs while building datasets that reflect realistic user expectations and behaviors.
Furthermore, A/B testing conversation flows generate comparative data that reveals user preferences and optimal interaction patterns. This approach helps identify which conversation structures lead to successful task completion and user satisfaction.
Synthetic Data Generation
Template-based conversation generation provides scalable methods for creating large volumes of training data. Specifically, these systems use predefined conversation templates with variable substitution to generate diverse dialogue examples. While this approach ensures coverage of specific scenarios, it may lack the natural variation found in human conversations.
In contrast, Large language model-assisted data augmentation techniques have revolutionized synthetic data generation. Modern LLMs can generate realistic conversation variations, paraphrase existing dialogues, and create entirely new conversation scenarios based on specific prompts and constraints.
Domain-specific scenario simulation enables targeted data generation for specialized applications. For instance, medical chatbot datasets require conversations that accurately reflect patient-provider interactions while maintaining clinical accuracy and appropriate bedside manner.
Data Source Considerations
Balancing domain coverage requires careful attention to conversation types and contexts. In customer support versus casual chatter or task-oriented dialogue. These issues often emerge when models are trained on uniform or homogenous datasets. To have high-performance models in real-time scenarios, the conversational AI dataset needs to embrace the widest possible variability.
Demographic and linguistic diversities are paramount in ensuring system building that serves everybody, rather than a few select groups. According to MIT’s Computer Science and Artificial Intelligence Laboratory, performance-oriented gaps can go up to 23%. These issues often emerge when models are trained on uniform or homogenous datasets. This can lead the system to misunderstand or underserve certain populations.
When we focus on data sourcing the centre of attention is always been legal and ethical concerns. While collecting the conversational datasets from different sources. Especially when users upload their personal or sensitive information. Privacy protections not only offer strong protections but also establish strict rules. The rules include data collection, data storage duration, and the persons who can access it.
What makes things even more paradoxical is the challenge of getting meaningful user consent in conversations that often shift unpredictably. Conversations often shift unexpectedly into sensitive territory. The users don’t always realize that their words are being captured for AI training. This makes consent more than just a checkbox—it becomes a complex, ongoing responsibility for anyone building conversational systems.
Finally, teams have to assess the trade-offs involved between the approaches from authentic and controlled data collection. Each of which is tending to some uses and limitations. Authentic data may give language with natural flow and real-world but mostly has unwanted noise or content or privacy issues.
Controlled collection provide input which are safe and clean. But if often lacks the edge cases, nuances, and spontaneity that come with actual conversations.
Annotation and Labeling Processes
Multi-Level Annotation Framework
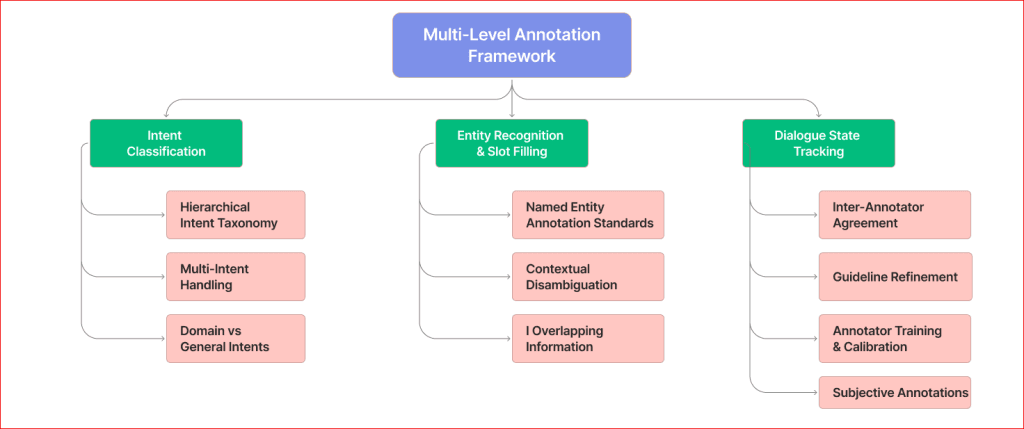
Intent Classification
Hierarchical intent taxonomies provide structured approaches to categorize user intentions in conversational data. Most modern dialog systems demand a 3-4-level hierarchy of intents, thereby supporting broad categorization and narrow recognition of intents.
Multi-intent handling presents ongoing challenges in conversational AI dataset annotation. Users frequently express multiple intents within single utterances, requiring annotation schemes that can capture these complex relationships. Research from Google’s Conversational AI team shows that 31% of user utterances contain multiple intents.
Domain-specific versus general intent categories require careful balance in annotation schemes. While general intents provide broad applicability, domain-specific categories often capture nuances critical for particular applications.
Entity Recognition and Slot Filling
Named entity annotation standards must accommodate the dynamic nature of conversational contexts. In contrast to standard NER tasks, conversational entity recognition has to deal with references. Which includes pronouns and contextual entities that span more than one conversation turn.
This contextual disambiguation of entities is a serious challenge in multi-turn conversations. The same surface form might be used to refer to different entities depending on the conversation history. Annotation guidelines must provide clear resolution strategies for these ambiguous cases.
Nested and overlapping entities are quite commonly encountered in conversational data. Annotation schemes are therefore needed that are capable of representing these complex relationships. For instance, a phrase may contain both person name and location reference requiring separate entity annotations.
Dialogue State Tracking
Turn-level state annotations capture the evolving information state throughout conversations. These annotations track what information the system has gathered. It includes what remains unknown, and what actions need to be taken to progress toward conversation goals.
Context carryover and reference resolution annotations ensure that models can maintain a coherent understanding across conversation turns. This includes tracking pronoun references, implicit information, and conversation topic evolution.
Conversations spanning multiple turns require the annotation scheme to capture the logical interflow and the structure of the conversation. With such annotations supporting your model in knowing when a conversation changes topics, returns to a previous talk, or requires clarification.
Annotation Quality and Consistency
Inter-annotator agreement metrics give us a quantitative way to measure annotation consistency. Pairwise agreement using Cohen’s kappa or agreements among multiple annotators using Fleiss’ kappa help identify where the annotation guidelines may need further refinement or where ambiguity exists intrinsically in the data.
Annotation guideline development requires iterative refinement based on real annotation challenges. Usually, the original set of guidelines goes from three to five rounds of edits as the annotators face edge cases and ambiguous examples.
The annotator training and calibration processes account for consistent application of annotation guidelines by various team members. Regular calibration sessions help maintain consistency as projects evolve and new team members join annotation efforts.
Subjective annotation poses a continuous challenge for conversational AI datasets. Areas such as sentiment, appropriateness, or conversation quality often require subjective decisions across annotators and contexts.
Tooling and Infrastructure
Labeling systems developed in-house versus those commercially available-for-sale have to trade flexibility out for time of development. Custom platforms can accommodate specific annotation requirements but require significant development resources. The off-the-shelf solutions offer faster deployment but do not support any specialized annotations.
Active learning approaches choose examples for annotation that would most improve model performance by prioritizing these annotations. These techniques can reduce annotation costs by 30-50% while maintaining dataset quality, according to recent studies from Carnegie Mellon University.
Version control and annotation history tracking become critical for large-scale annotation projects. These systems enable quality auditing, annotator performance analysis, and systematic correction of annotation errors discovered later in the development process.
Quality Assurance and Dataset Validation
Data Quality Metrics
Coverage Analysis
Intent distribution analysis ensures that conversational AI datasets provide adequate coverage across different user intentions. Particular challenges exist for long-tail intent coverage, as the infrequent ones may nonetheless be key factors for ensuring user satisfaction.
Metrics of vocabulary diversity help analyze whether datasets possess the adequate linguistic variation necessary to make possible a robust training of the model. Out-of-vocabulary rates recorded in held-out test sets provide some indication of how complete a dataset is or how well a constitution of it would generalize into a working model.
Conversation length and complexity distributions will inform whether datasets represent the range of interactions systems will see out there in production. Question-answer pairs are far from being like multi-turn problem-solving conversations in practice.
Bias Detection and Mitigation
Demographic bias analysis examines whether conversational AI datasets represent different user populations fairly and accurately. Systematic underrepresentation of certain groups can lead to performance disparities in deployed systems.
Topic and domain bias analysis acts as a filter to detect the over-representation of certain types of conversations or subject areas in the dataset. This type of analysis guarantees that the stage models work on an equal footing for different use cases and, in fact, in different conversation contexts.
Geographical and cultural representation analyses gain immense significance while deploying conversational AI systems at a global scale. There are immense differences in communication styles, systems of politeness and organization of a discourse in different parts of the world or between separate communities.
Validation Methodologies
Statistical Validation
The distribution analysis and outlier checking may highlight possible data quality issues or annotation inconsistencies. Statistical validation, in fact, may reveal other causes of systematic bias, annotation errors, or problems in data collection-whether or not these might ever be evident to a manual reviewer.
Temporal consistency cross-validation splits endeavor to provide consistent quality for conversational AI datasets over time. Temporal splits can reveal whether data collection processes introduced systematic changes or biases during dataset development.
Dataset drift monitoring tracks how conversational patterns and user behaviors evolve over time. This monitoring helps identify when datasets need updates or refreshing to maintain production performance.
Human Evaluation
Expert review processes provide a qualitative assessment of the dataset quality and annotation accuracy. These experts, an essential resource, identify subtle errors or inconsistencies that validation systems may miss.
User study validation checks whether conversational AI datasets are the way to represent real user expectations and behaviors fit. These studies also help in aligning synthetic or curated data with real-world user behavior.
Alternately, Comparative analysis against existing benchmarks puts the dataset quality into perspective and identifies aspects that require attention. Benchmarks also help community acceptance and reproducible research.
Quality Monitoring
Automated quality checks with alerts ensure that the dataset maintains its quality during the addition of new data or update in the annotation. These systems serve to identify potential problems such as inconsistencies in annotation, statistical anomalies, or errors in format.
Performance regression testing prevents the dataset changes resulting in negative impact on model performance. These tests help validate that dataset improvements actually benefit downstream applications.
Dataset versioning and rollback strategies provide safety nets for dataset development. This helps comparative testing of dataset adjustments and fast retrieval if any potential concerns develop after an update is carried out.
Privacy, Ethics, and Compliance

Privacy Protection Measures
Personally identifiable information detection and anonymization techniques protect user privacy in conversational datasets. Advanced PII detection systems can identify not just obvious identifiers like names and phone numbers, but also quasi-identifiers that might enable re-identification when combined.
Differential privacy applications in conversational data provide mathematical guarantees about privacy protection while enabling useful dataset creation. These methods add carefully controlled noise to the datasets to preclude individual identification while preserving the overall statistical profile.
Data retention and deletion policies provide for transparent guidelines regarding the storage period of conversational data and the timing for removal. Considerations must be balanced between the needs of research and development as well as privacy protections.
GDPR, CCPA, and regional compliance requirements do place on conversational AI data set development some legal obligations. Being in compliance means having not only technically compliant measures but also procedural safeguards and documentation practices.
Ethical Considerations
A consented and transparent data usage practice should always leave an inbound data provider with an understanding of what is being done to their conversations. Meaningful consent for conversational data has to include a clear explanation of potential uses, sharing arrangements, and retention.
Bias mitigation strategies address systematic unfairness caused by conversational AI datasets and the models arising therefrom. These strategies must operate at multiple levels: data collection, annotation, and validation processes.
Representation and inclusivity must be present in the data construction so that conversational AI systems will account for a variety of users. One must take deliberate action to incorporate diverse perspectives and communication styles.
Potential misuse prevention and safeguard mechanisms act as blocks against harmful use cases in liaison with conversational AI datasets. It may encompass restrictions on usage, control over the access to information, and mechanisms to keep an eye on abuses.
Safety and Content Moderation
Inappropriate content detection and filtering remove unwanted content from conversational AI datasets whilst preserving valid training samples. The automated filtering system should be set up that does not block the inappropriate content worthy of picking for safety, lest this leads to over-censorship curtailing model capabilities.
Recognizing adversarial inputs readies conversational AI systems against inputs that malicious players have deliberately designed to draw forth inappropriate responses. Adversarial examples for conversational AI might include trying to extract training data or trying to instruct the system to create harmful content or change its behavior.
Red-teaming and safety evaluation protocols provide systematic approaches to identifying potential risks and vulnerabilities in conversational AI datasets and trained models. These evaluations help identify edge cases and failure modes before deployment.
Dataset Deployment and Maintenance
Production Pipeline Integration
Data pipeline architecture and scalability considerations ensure that conversational AI datasets can support production workloads effectively. Pipeline design must accommodate both batch training processes and potentially real-time dataset updates.
Trade-offs of real-time versus batch processing impact the speed at which new data is ingested into conversational AI systems or the tempo of changes in user behavior. Therefore, real-time processing allows quicker adaptation but makes the infrastructure more complex.
MLOps integration and automated retraining triggers create systematic approaches to keeping conversational AI models current as datasets evolve. These systems can automatically detect when the dataset changes warrant model retraining.
Versioning and Lifecycle Management
Dataset versioning strategies help track changes systematically, supporting reproducible research and development. Version control for conversational AI datasets must recognize not only changes in data but also updates in annotation.
Backward compatibility, as well as migration planning, guarantees that existing applications or research projects are not disrupted when datasets are updated. Migration policies must, therefore, reason out between innovations and stability.
The performance monitoring and dataset-refresh cycles always keep the conversational-AI datasets updated on the basis of production performance and changing needs of users. These cycles help maintain model accuracy over time.
Community and Open Source Considerations
Data-sharing and collaboration protocols ensure wider participation from the scientific community while retaining the sanctity of sensitive information and intellectual property. Open-dataset initiatives help fast-track research, which almost always sets the privacy and ethical issues on their path.
Benchmark creation and standardization help establish common evaluation frameworks for conversational AI research. Standardized benchmarks enable comparison across different approaches and facilitate reproducible research.
Contributing to research community datasets supports broader advancement in conversational AI while potentially benefiting from community contributions and validation.
Future Directions and Emerging Trends
Some of the key trends shaping future requirements in conversational AI dataset development are ongoing major changes in the field. Multimodal datasets integrating voice, visual, and textual modalities gain significance as conversational AI systems move away from pure text interactions. With greater acceptance of cross-lingual and multilingual approaches, more applications are seeing global implementation.
Cross-lingual and multilingual approaches address the global nature of today’s applications. State-of-the-art conversational AI datasets shall obviously promote code switching and cultural adaptation along the lines of language-specific conversational patterns that depict real-world linguistic diversity.
Privacy-preserving methods of dataset development, including the application of federated learning and state-of-the-art anonymization, allow new collaborative dataset development forms so that strong privacy can be preserved.
Conclusion
Before anything else, the dataset deserves utmost care. It is not just about collecting dialogues but collecting them while ensuring annotation quality, privacy constraints, and the adaptability of the dataset to changes in time. Everything in the chain of events leading up to this end is critical when the cause at hand is the development of AI that is considered human-like and can be trusted by real human beings.
Quality assures an operation-improving workflow from the very first dayrather than as an afterthought. Comparing and controlling the dataset periodically, as per evolving user requirements and changing conversational styles, shall guarantee that the systems stay updated and responsive.
Constructing a good-quality dataset requires a lot of time and work that ultimately pay off many times over later in the development phase, easing issues in production, while finally providing users with qualitative and gratifying experiences.
Something easy to overlook: your dataset influences not only your product. This collaborative landscape is built on one tool or another—your work trickles down the process to help other researchers, developers, and teams create better tools as well. A commitment to data quality raises the bar for everybody.
FAQs
Ans: – Traditionally, production systems require 50k to over 500k annotated conversations. Depending on the complexity of the domain and the requirements of the use case. Nevertheless, quality usually matters the most.
Ans: – Yes, we offer conversation AI datasets in various formats, such as text, audio or video. We also offer off-the-shelf and custom datasets as per your specifications and requirements.
Ans: – A basin of telling can include PII detection and enforce differential privacy techniques where applicable. Getting consent along the entire process, maintaining strict control over access, and so forth throughout the whole life cycle of the dataset.
Ans: – Normally, a complete dataset requires a period of between 1 to 3 months and possibly more. In the time frame the phases include data gathering, annotation, quality assurance, and validation. Yet, this time frame drastically depends on your scope and quality requirements.

You Might Like

July 24, 2025
Transform Your Data: Classification & Indexing with Macgence
In an AI‑driven world, the quality of your models depends entirely on the data you feed them. People tend to focus on optimising model architecture, reducing the time of training without degradation of accuracy, as well as the computational cost. However, they overlook the most important part of their LLMs or AI solution, which is […]

July 22, 2025
Stress Test Your AI: Professional Hallucination Testing Services
In the age of LLMs and gen AI, performance is no longer just output—it’s about “trust”. One of the biggest threats to that trust? Hallucinations. These seemingly confident but factually incorrect outputs can lead to misinformation, massive brand damage, which can cause millions, compliance violations, which can cause legal issues, and even product failure. That’s […]

July 21, 2025
How Smart LLM Prompting Drives Your Tailored AI Solutions
In today’s AI world, every business increasingly relies on LLMs for automating content creation, customer support, lead generation, and more. But one crucial factor people tend to ignore, i.e., LLM Prompting. Poorly crafted prompts result in hallucinations or sycophancy—even with the most advanced models. You might get chatty copy but not conversions, or a generic […]