


A Guide to Language Data Annotation
Language data annotation is the process of labeling data in text, audio, and video formats. This is done so that data can be used by machine learning algorithms. It is used in various AI applications like chatbots and virtual assistants. The prime reason behind the requirement of language data annotation is the varied and complex nature of human language. Humans interact with each other in multiple ways by using different languages, accents, and dialects. Hence, language data annotation becomes crucial to ensure quality and accuracy in the datasets required for training AI and ML models. If you are on a hunt to source quality data sets to train your NLP models, then do check out Macgence. Their in-house experts curate the best quality data sets to optimize your AI models.
Annotators label the text, video, and audio data with notes or metadata so that it can be understood by NLP and other AI models. In this blog, we’ll discuss in-depth about language data annotation. Keep reading!
What is Language Data Annotation
So, we have discussed that the process of assigning metatags and labels to linguistic components in a data set is known as language data annotation. This method is also known as NLP.
One must understand that computers can never learn to respond accurately if they are fed with large volumes of data. Doing this will slow down the processing of the system and will lead to inaccurate outcomes. So, data needs to be properly prepared before being fed to the AI/ML models and computers so that optimized results can be generated. Language data annotation is the key step to preparing data sets for feeding a system. With the help of NLP/language data annotation, AI models can easily understand the tone of human language. By integrating it with AI or NLP, models can perform tasks like entity recognition, sentiment analysis, or part-of-speech tagging.
Data annotators are employed for this purpose. They add metatags and labels to the content of the data so that AI models can identify patterns from it. Based on the identified patterns, these models produce future results. Hence, language data annotation is one of the most crucial parts of training an AI model.
Types of Language Data Annotation Tasks
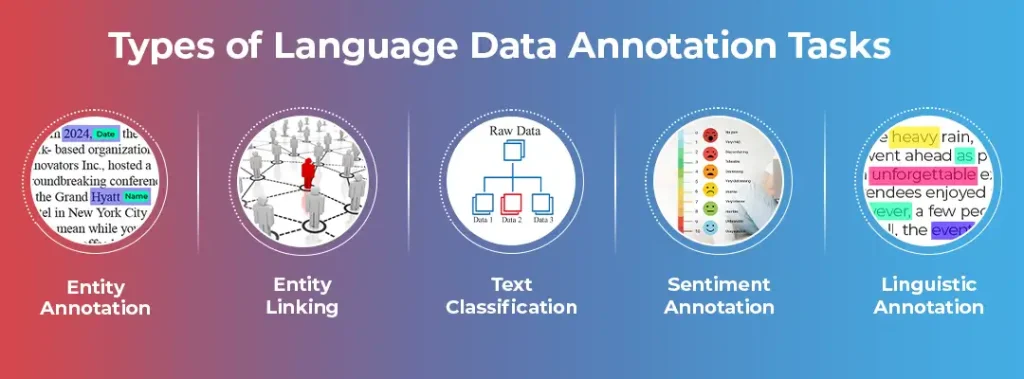
Following are some of the commonly used language data annotation types:
Entity Annotation:
The process of entity annotation involves identifying and tagging entities (words or phrases in case of text) like certain keywords or names. Entity annotation is crucial for training natural language processing models used to develop chatbots and virtual assistants. The combination of entity annotation and entity linking provides an upgraded learning environment for NLP models. Entity linking is discussed below.
Entity Linking:
After entity annotation, the specific entities are located and labeled. Further, entity linking connects these entities to larger data repositories. In this process, a specific identity is assigned to an entity from the textual data, for example the name of a company or their contact information. Entity linking is aimed at improving search results and providing a better user experience.
Text Classification:
It is a broader way of categorizing and labeling data. Text classification or categorization involves the addition of labels to an entire body or line of text. Annotators read and analyze texts carefully, determine the main topic and idea behind the text, and further classify it as per the predetermined categories.
Sentiment Annotation:
Sentiment annotation is aimed at training AI models to label emotions, sentiments, and opinions from textual data. However, it is one of the most challenging tasks under language data annotation. Sometimes, even humans fail to understand the actual meaning and emotion behind a text so it is even more difficult for machines to do this task. However, sentiment analysis/annotation is here for the rescue. By feeding sentiment-annotated textual data to AI models, they are trained to understand emotions and sentiments.
Linguistic/Corpus Annotation:
A corpus in NLP Is a collection of textual or audio data that is organized in the form of data sets. To label a corpus, language data is tagged in texts and audio recordings. Further, annotators detect the semantic and grammatical elements in the data. This subset of language data annotation is used to curate AI training data sets for NLP solutions like search engines, translation apps, chatbots, and more.
Why Macgence?
Without accurate and comprehensive language data annotation, AI models would struggle to understand and interpret human language effectively. This foundational step ensures that AI systems can deliver precise and reliable outcomes. AI & ML are evolving at a high pace and if you want your business to grow, you have to integrate AI into your organization. Check out Macgence, we are your go-to AI partners as we provide the best language data annotation datasets in the entire market.
With Macgence, you get outstanding quality, scalability, expertise, and support. Whether you have a small-scale startup or a large corporation, Macgence has always got your back. Reach out to us today at www.macgence.com!
FAQs
Ans: – Language data annotation is the process of labeling data in text, audio, and video formats. This is done so that data can be used by machine learning algorithms. It helps these models understand and process human language accurately.
Ans: – Language data annotation is important because it is the key step to preparing datasets for feeding a system. With the help of NLP/language data annotation, AI models can easily understand the tone of human language. Moreover, it enhances the training process and outcomes of an AI model.
Ans: – The process of entity annotation involves identifying and tagging entities (words or phrases in case of text) like certain keywords or names. It is important for training NLP models, especially those used in chatbots and virtual assistants.
Ans: – Language data annotation helps AI and ML models to understand and interpret human inputs in a better way. This ensures that quality and relevant results are produced by the AI model.
Ans: – For sourcing the best data sets for the purpose of language data annotation, look no further than Macgence. They have in-house experts who curate the best training data sets for your NLP model.
 Previous Blog
Previous Blog



You Might Like

June 18, 2026
Mastering Teleoperation Data Annotation for Robotics
The demand for intelligent robotics and autonomous systems is accelerating at an unprecedented rate. As machines take on increasingly complex tasks, developers face a significant hurdle: teaching robots how to navigate the unpredictable nature of real-world environments. Teleoperation bridges the gap between human intelligence and machine learning by allowing humans to guide robots through specific […]

June 17, 2026
Choosing the Right Image Annotation Companies for AI Growth
Behind every successful computer vision model is an enormous volume of high-quality labeled data. AI systems depend entirely on this foundational layer to understand, interpret, and react to the visual world. Image annotation serves as the bedrock of computer vision. Without it, the sophisticated algorithms powering modern technology simply cannot function. Countless industries rely heavily […]

June 15, 2026
Why Teleoperation Data Collection Is Critical for AI-Powered Robotics?
Teleoperation lets a human operator remotely control a robot, drone, or vehicle from a distance, often using cameras, sensors, and a control interface. As robotics and autonomous systems move from labs into warehouses, farms, and city streets, they need vast amounts of real-world operational data to learn from. That’s where teleoperation data collection comes in. […]