


Data Labeling: A Comprehensive Guide
If you possess an enormous quantity of unlabeled data or are new to Data Labeling, this guide is precisely what you need. This comprehensive guide provides a thorough understanding of the fundamentals of data labeling, from various kinds of data labeling to the difficulties faced during the process and recommended practices for success.
What is Data Labeling?

Data Labeling gives clear labels to raw data so machines can understand it. It involves adding important tags and annotations like keywords, categories, and attributes. This helps artificial intelligence tools, like algorithms, train themselves. It is crucial for machine learning because it helps machines find patterns in data accurately. It plays a big role in making machine learning technology work well.
Labeling data can be done in two ways: using automated tools or manually by humans. The manual method involves reviewing and identifying information based on established standards to ensure accuracy. Although it may seem more expensive and time-consuming compared to automation, its benefits include reliable results, making it a worthwhile option.
On the other hand, automatic data labeling utilises machine learning algorithms to speed up and simplify the tagging process. The system learns to recognise important patterns in the data to assign relevant labels without human involvement. It is crucial to exercise caution when working with complex or subjective datasets, as the accuracy of automatic labeling may not always be perfect.
What are the different types of Data Labeling?
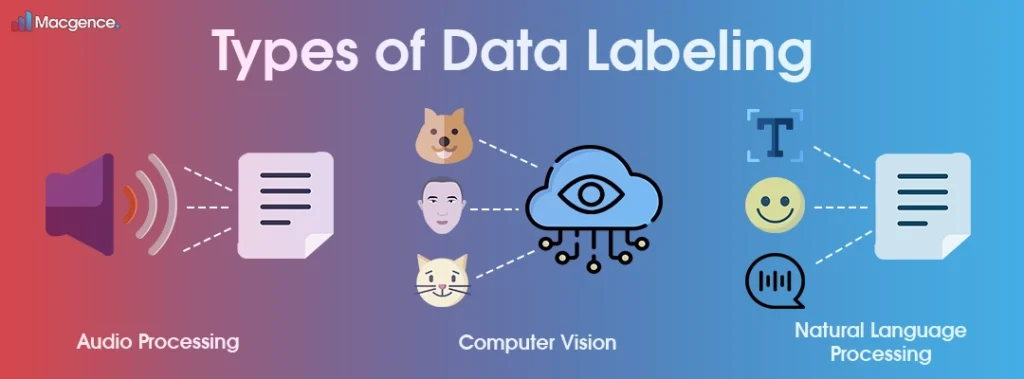
Let’s explore the different types of data labeling:
- Image labeling: Image labeling is a technique where relevant labels or tags are assigned to identify elements in an image. It assists machine learning algorithms in recognising attributes and distinguishing objects. Examples include image classification, where images are tagged based on specific criteria, enhancing algorithms’ understanding of images.
- Text labeling: This technique adds helpful information to written materials like articles, essays, blogs, and social media posts. It involves assigning labels and tags that describe specific attributes in the text. This can include analysing emotions, identifying people’s names, and categorising topics.
- Audio labeling: Audio labeling focuses on annotating audio data, such as speech recordings or sound clips, with relevant metadata or tags. This can involve tasks like speech-to-text transcription, speaker identification, or emotion detection, aiding algorithms in understanding and analysing audio content.
- Video labeling: Video labeling is assigning labels or annotations to video data. It helps identify and track objects, activities, or events within videos. Video labeling tasks may include object detection, action recognition, or scene classification, enhancing the capabilities of machine learning algorithms in video analysis.
Benefits and Challenges of Data Labeling

Data Annotation offers several benefits and comes with its fair share of challenges. It can improve the performance of AI models by making them more accurate and efficient. When data is labeled with descriptions, AI models can recognize patterns and make better predictions. This can result in improved decision-making and increased operational efficiency.
Data labeling can also reduce errors and biases in the training data. When data is accurately and consistently labeled, the quality of the training dataset is improved. This can lead to the better overall performance of AI models. Essentially, it helps ensure that the training data is of high quality, which can result in more accurate and reliable predictions.
Despite its benefits, it also comes with challenges that must be recognized. One major challenge is the high cost and time required to label large datasets. It can be time-consuming and expensive, particularly when specialized expertise in a specific domain is necessary.
Another challenge to overcome is ensuring consistency and precision in labeled data. Interpretations of labeling guidelines differ from person to person; thus, inconsistency in labeled information could occur. An inaccurate and not reliable AI model can result from such discrepancies.
Overall, it is essential for training accurate and effective AI models. While some challenges are associated with data labeling, the benefits of improved accuracy, reliability, and reduced errors and biases make it a necessary step in developing AI models.
Best practices for Data Labeling

To ensure the optimal performance of AI models, implementing effective Data Labeling practices is essential for accuracy and efficiency. Here are some of the best data labeling practices that will help you achieve success in your next project:
- Clearly define labeling guidelines: Defining specific guidelines and criteria for labeling is essential before labeling the data. This will guarantee accuracy and consistency throughout the process.
- Provide comprehensive training: To optimise accuracy in data labeling, it is essential to offer comprehensive training on guidelines and criteria for labelers. This will enable a clear knowledge of requirements, ensuring precise data labeling. Providing detailed practical scenarios and examples helps better understand the task’s nuances.
- Reviewing labeled data: Labeled data need regular reviews to ensure it follows the labeling guidelines. These reviews help catch mistakes or differences in the labeling process. By doing these checks, you can spot errors and fix them.
- Balancing quality and quantity: It is important to balance the quality and quantity of labeled data. While increasing the amount of labeled data can improve accuracy, it is equally important to ensure the availability of high-quality labeled data.
Conclusion
In conclusion, Data Labeling is vital in developing AI and machine learning models. It involves categorising data so that the machines can understand and use it. Properly labeled data is essential for training algorithms to recognise patterns and make accurate predictions. While data labeling can be a time-consuming and expensive process, the benefits it provides are enormous. By following the practical tips outlined in this guide, businesses can ensure that their data labeling efforts are effective and efficient. Ultimately, the quality of the labeled data will determine the accuracy and effectiveness of the AI models built on it.
Get started with Macgence
Macgence provides complete AI/ML data solutions, including top-notch data labeling services. Our approach involves a managed crowd and a rigorous methodology to ensure accurate labeling. By using our services, you can create better AI solutions faster. At Macgence, we’re committed to helping you make the most of your data and driving advancements in the AI industry.
Frequently Asked Questions (FAQ’S)
Q1. How to do data labeling?
Data labeling assigns labels or tags to raw data, aiding machine learning algorithms in understanding and predicting patterns accurately. It can be done manually or automatically using tools like image, text, audio, or video labeling techniques.
Q2. What is the difference between data labeling and annotation?
Data labeling involves assigning labels or tags to raw data for machine learning, while data annotation refers to adding additional information or metadata to the labeled data.
Q3. What are examples of labeled data?
Examples of labeled data include an image of a dog with the label “dog” or “animal” attached to it or a video with timestamps and labeled objects, such as cars, trees, or people.
 Previous Blog
Previous Blog



You Might Like

June 18, 2026
Mastering Teleoperation Data Annotation for Robotics
The demand for intelligent robotics and autonomous systems is accelerating at an unprecedented rate. As machines take on increasingly complex tasks, developers face a significant hurdle: teaching robots how to navigate the unpredictable nature of real-world environments. Teleoperation bridges the gap between human intelligence and machine learning by allowing humans to guide robots through specific […]

June 17, 2026
Choosing the Right Image Annotation Companies for AI Growth
Behind every successful computer vision model is an enormous volume of high-quality labeled data. AI systems depend entirely on this foundational layer to understand, interpret, and react to the visual world. Image annotation serves as the bedrock of computer vision. Without it, the sophisticated algorithms powering modern technology simply cannot function. Countless industries rely heavily […]

June 15, 2026
Why Teleoperation Data Collection Is Critical for AI-Powered Robotics?
Teleoperation lets a human operator remotely control a robot, drone, or vehicle from a distance, often using cameras, sensors, and a control interface. As robotics and autonomous systems move from labs into warehouses, farms, and city streets, they need vast amounts of real-world operational data to learn from. That’s where teleoperation data collection comes in. […]